TensorRT Version: 8.0.1.6 GPU Type: GTX 1060 Nvidia Driver Version: 461.33 CUDA Version: 11.2 CUDNN Version: 8.1 Operating System + Version: Windows 10 / Ubuntu 18.04 Python Version (if applicable): 3.7 TensorFlow Version (if applicable): 2.6/2.7-nightly
Description
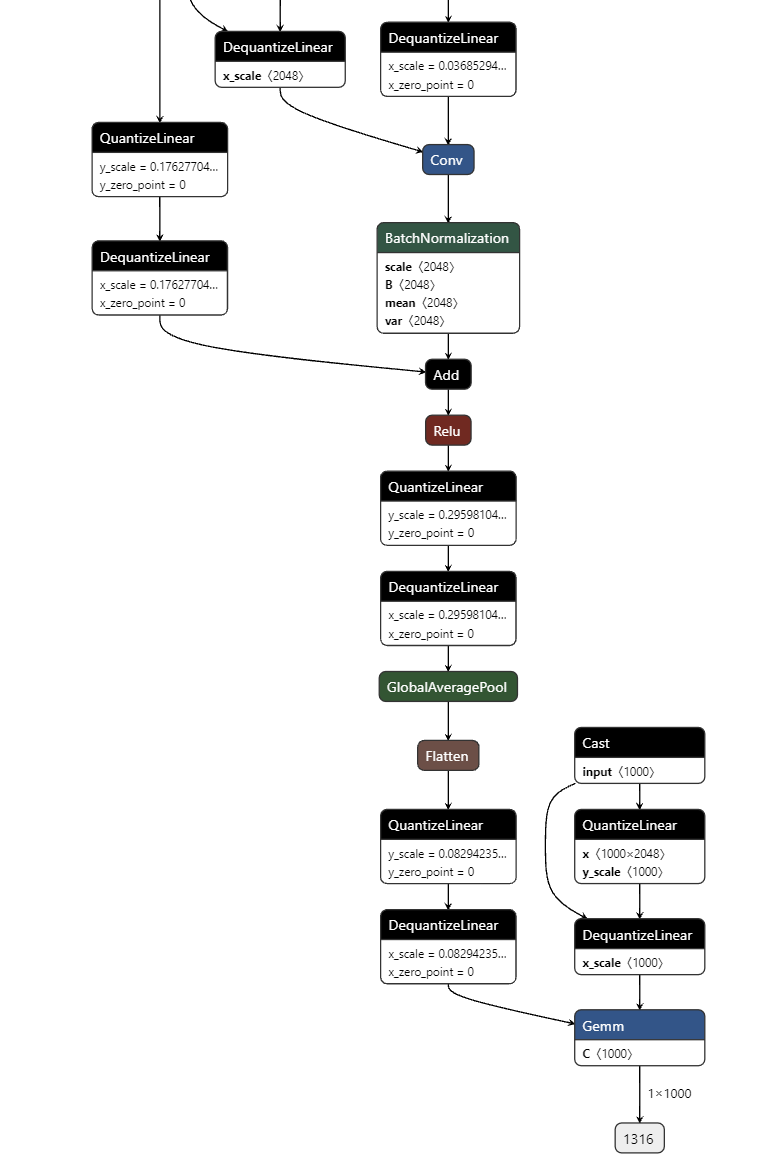
I am training QAT models in tensorflow 2.6.0 and later versions. I am only turning on the QAT nodes during the final 5 epochs (fine-tuning with QAT). And as recommended by TensorRT, I have been using symmetric quantization for both inputs and weights of quantizable ops (Conv2D). Inputs are per-tensor quantized and weights are per-channel quantized as recommended. And as you can see in Figure(1) below, after converting my tensorflow trained model to ONNX (opset 13), the required Q/DQ ops are added properly. And I am also able to successfully parse and benchmark this with trtexec (PASSED TensorRT.trtexec). I have attached the full verbose log below.
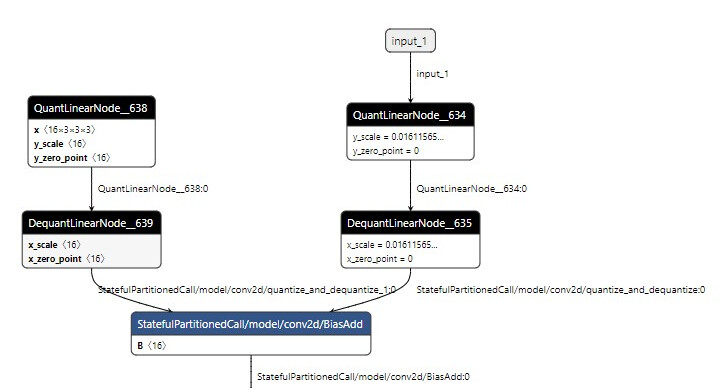
But during the engine building, I see multiple such messages. For example, it says quantization data is missing for QuantLinearNode__574_quantize_scale_node but as you can see in the ONNX model visualization in Figure(1), QuantLinearNode__574 has all the required quantization data i.e. scale=0.01611565239727497 and zero_point=0
This is pretty much happening to all QuantLinearNodes that were added to inputs of Conv2d op.
Is this expected behaviour? and are these messages safe to be ignored?
For reproduction, I have created a simple QAT trained resnet model and uploaded it in ONNX format
[09/17/2021-13:54:53] [V] [TRT] Setting a default quantization params because quantization data is missing for QuantLinearNode__574_quantize_scale_node
[09/17/2021-13:54:53] [V] [TRT] Setting a default quantization params because quantization data is missing for QuantLinearNode__582_quantize_scale_node
[09/17/2021-13:54:54] [V] [TRT] Setting a default quantization params because quantization data is missing for QuantLinearNode__598_quantize_scale_node
[09/17/2021-13:54:54] [V] [TRT] Setting a default quantization params because quantization data is missing for QuantLinearNode__614_quantize_scale_node
...
...
Hi,
Request you to share the ONNX model and the script if not shared already so that we can assist you better.
Alongside you can try few things:
validating your model with the below snippet
check_model.py
import sys
import onnx
filename = yourONNXmodel
model = onnx.load(filename)
onnx.checker.check_model(model).
2) Try running your model with trtexec command. https://github.com/NVIDIA/TensorRT/tree/master/samples/opensource/trtexec
In case you are still facing issue, request you to share the trtexec “”–verbose"" log for further debugging
Thanks!
Verbose log of trtexec
I can successfully run the model with trtexec, but I am concerned about the messages about “missing quantization data” while running trtexec when there IS quantization data present, see Figure(1)
These logs do not indicate a definite problem. The log is produced after the graph is optimized. We do a pass over all nodes, and nodes whose output tensors don’t have quantization scales are assigned a default scale of 1 (sort of like a NoP scale). That’s what the “default quantization” means in the log.
In case of the above log tells us that there are Q nodes (574, 582) whose outputs are getting assigned the default scale (1). This is fine even though it may sound wrong. In other words, Q nodes are left in the graph after graph fusion optimization. One Q node is usually expected (to quantized the network input), but more than one Q node usually indicates that Q/DQ nodes are placed in places that prevent fusion.
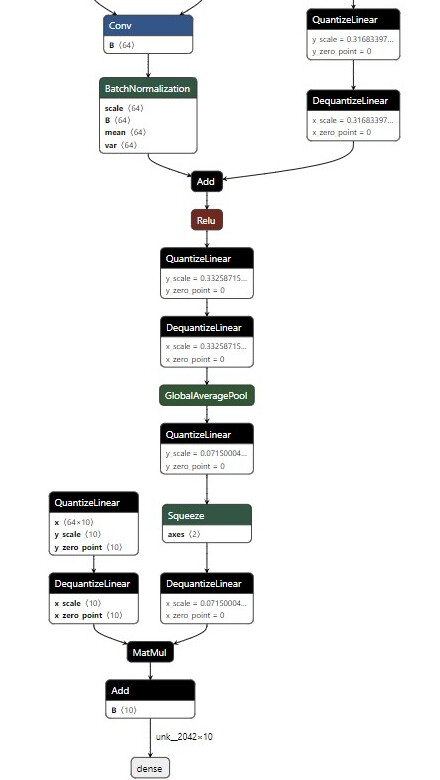
One thing we’ve observed is the you model graph doesn’t follow the full recommendations from TensorRT. Like the residual branch in the model has no additional QDQ pair. For example a residual branch in the onnx model graph looks like
Basically the identity branch should have a QDQ pair. Otherwise, this might lead to suboptimal fusions which can leave dangling Q/DQ nodes which can be expensive as explained in the documentation : Developer Guide :: NVIDIA Deep Learning TensorRT Documentation
[10/02/2021-15:41:30] [V] [TRT] Setting a default quantization params because quantization data is missing for QuantLinearNode__628_quantize_scale_node
[10/02/2021-15:41:30] [V] [TRT] Setting a default quantization params because quantization data is missing for DequantLinearNode__1173_quantize_scale_node
[10/02/2021-15:41:30] [V] [TRT] Setting a default quantization params because quantization data is missing for StatefulPartitionedCall/model/global_average_pooling2d/Mean
[10/02/2021-15:41:30] [V] [TRT] Setting a default quantization params because quantization data is missing for StatefulPartitionedCall/model/dense/MatMul + StatefulPartitionedCall/model/dense/BiasAdd/ReadVariableOp__623 + (Unnamed Layer* 1115) [Shuffle] + unsqueeze_node_after_StatefulPartitionedCall/model/dense/BiasAdd/ReadVariableOp__623 + (Unnamed Layer* 1115) [Shuffle] + StatefulPartitionedCall/model/dense/BiasAdd
I managed to run the resulting ONNX model with trtexec, and this time I noticed that all the Q/DQ are fused and there are no dangling Q/DQ ops, but for these four ops. IIUC QuantLinearNode__628 and DequantLinearNode__1173 are expected since they will quantize and dequantize the input and the output respectively. And the last op is for the dense layer which I intentionally did not quantize. But I am not very sure about the global_average_pooling2d warning.
My follow-up question is, do I need to explicitly add Q/DQ ops to the final dense layer to trigger TensorRT to run global_average_pooling2d node in INT8 mode? (as shown below)
I tried running trtexec in verbose mode on my host (GTX 1060) and on my AGX Xavier (JP 4.6)
On 1060
[10/04/2021-21:34:43] [V] [TRT] Setting a default quantization params because quantization data is missing for QuantLinearNode__628_quantize_scale_node
[10/04/2021-21:34:43] [V] [TRT] Setting a default quantization params because quantization data is missing for DequantLinearNode__1173_quantize_scale_node
[10/04/2021-21:34:43] [V] [TRT] Setting a default quantization params because quantization data is missing for StatefulPartitionedCall/model/global_average_pooling2d/Mean
[10/04/2021-21:34:43] [V] [TRT] Setting a default quantization params because quantization data is missing for StatefulPartitionedCall/model/dense/MatMul + StatefulPartitionedCall/model/dense/BiasAdd/ReadVariableOp__623 + (Unnamed Layer* 1115) [Shuffle] + unsqueeze_node_after_StatefulPartitionedCall/model/dense/BiasAdd/ReadVariableOp__623 + (Unnamed Layer* 1115) [Shuffle] + StatefulPartitionedCall/model/dense/BiasAdd
On AGX Xavier
[10/04/2021-21:26:39] [V] [TRT] Setting a default quantization params because quantization data is missing for QuantLinearNode__628_quantize_scale_node
[10/04/2021-21:26:39] [V] [TRT] Setting a default quantization params because quantization data is missing for DequantLinearNode__1173_quantize_scale_node
[10/04/2021-21:26:39] [V] [TRT] Setting a default quantization params because quantization data is missing for Reformatting CopyNode for Input Tensor 1 to StatefulPartitionedCall/model/quant_conv2d_56/transpose__614 + QuantLinearNode__1188_quantize_scale_node + StatefulPartitionedCall/model/quant_conv2d_56/BiasAdd + StatefulPartitionedCall/model/add_26/add + StatefulPartitionedCall/model/activation_54/Relu
[10/04/2021-21:26:39] [V] [TRT] Setting a default quantization params because quantization data is missing for Reformatting CopyNode for Input Tensor 0 to StatefulPartitionedCall/model/global_average_pooling2d/Mean
[10/04/2021-21:26:39] [V] [TRT] Setting a default quantization params because quantization data is missing for StatefulPartitionedCall/model/global_average_pooling2d/Mean
[10/04/2021-21:26:39] [V] [TRT] Setting a default quantization params because quantization data is missing for StatefulPartitionedCall/model/dense/MatMul + StatefulPartitionedCall/model/dense/BiasAdd
In this graph the matmul operation is performed in float. Add Q/DQ in front of the mamul ( StatefulPartitionedCall/model/dense/MatMul ) input and weights and you get int8 matmul.
However, the GAP operates in float so the output of the Conv ( StatefulPartitionedCall/model/quant_conv2d_56/BiasAdd ) is also in float and you have a dangling DQ ( DequantLinearNode__1173 ).
Add another Q/DQ pair before the GAP node. The Q node from this new pair of Q/DQ propagates backward over the ReLU and fuses with the Conv ( StatefulPartitionedCall/model/quant_conv2d_56/BiasAdd ). Now its output is int8.
It should look like this (from our reference model):
For some reason, tf2onnx keeps adding a squeeze layer between the Q and DQ ops for the final dense layer, does it still result in optimal fusion? I could use graph surgery to move it before the Q op, is it required?
I can see a single Quantize layer present, this is right after the input
[10/06/2021-00:53:39] [V] [TRT] Setting a default quantization params because quantization data is missing for QuantLinearNode__634_quantize_scale_node
I haven’t tried doing it yet. Also, apart from QuantLinearNode__634_quantize_scale_node, I can still see that there are few layers that have no names but still pop up in the logs here is an example.
[10/06/2021-00:53:35] [V] [TRT] Setting a default quantization params because quantization data is missing for
[10/06/2021-00:53:35] [V] [TRT] Tactic: 1 Time: 0.005836
[10/06/2021-00:53:35] [V] [TRT] Fastest Tactic: 1 Time: 0.005836
How do I find the nodes with missing names?
By reading this I assumed that QuantLinearNode__634_quantize_scale_node is supposed to be present to quantize the network input
We looked into your onnx model, we have not identified any problem. As mentioned in previous messages, these warnings are not harmful. Also this will be fixed for Q/DQ layers to make sure ‘missing’ log doesn’t appear (since they always have “missing quantization data”).