Got Tensorflow running, but it is not able to see the GPUs, it is running only on CPU, Please Help!
Hi @glenbhermon, did you install TensorFlow for Jetson from here?
Or can you try l4t-tensorflow container and confirm that sees your GPU?
I’ve followed the guide previously to install and have faced the same issue. Although I tried the container option that you suggested and tensorflow is able to see the GPU. However, scikit-learn is coming up with some unusual error, the screenshot is attached for your reference. Please Help!

Hi! I just checked and found out that even via Docker the GPUs aren’t visible to tensorflow, it worked just once initially. Please Help!

Can you try running this first?
export LD_PRELOAD=/usr/lib/aarch64-linux-gnu/libgomp.so.1
Can you also try the nvcr.io/nvidia/l4t-tensorflow:r35.1.0-tf1.15-py3 just to confirm it’s not related to that build of TF 2.9?
Also, can you successfully run deviceQuery sample on your device outside of container?
cd /usr/local/cuda/samples/1_Utilities/deviceQuery
sudo make
./deviceQuery
Yes I actually tried this:
but it’s the same error that comes, I even went down the remote jupyter lab route - same error!
Yes! here’s a screenshot showing the status of both the containers:

Yup, attaching that too:

Please Help!
(P.S. Thank you for all the support thus far)
OK, since the TF 1.15 container is not able to detect your GPU either, my guess is that something has gone awry with your system/driver configuration and that you may just want to re-flash your device. What’s the version of JetPack-L4T that you are running? (you can check this with cat /etc/nv_tegra_release)
Also, what does your cudacheck.py run? This is what I get from TF2 on Orin when I run tf.config.experimental.list_physical_devices('GPU')
2022-11-23 13:53:23.374568: I tensorflow/stream_executor/cuda/cuda_gpu_executor.cc:938] could not open file to read NUMA node: /sys/bus/pci/devices/0000:00:00.0/numa_node
Your kernel may have been built without NUMA support.
2022-11-23 13:53:23.448994: I tensorflow/stream_executor/cuda/cuda_gpu_executor.cc:938] could not open file to read NUMA node: /sys/bus/pci/devices/0000:00:00.0/numa_node
Your kernel may have been built without NUMA support.
2022-11-23 13:53:23.449181: I tensorflow/stream_executor/cuda/cuda_gpu_executor.cc:938] could not open file to read NUMA node: /sys/bus/pci/devices/0000:00:00.0/numa_node
Your kernel may have been built without NUMA support.
[PhysicalDevice(name='/physical_device:GPU:0', device_type='GPU')]
Hi! actually even I thought the same, and I’ve flashed it thrice before reaching out!
Here’s the screenshot for the JetPack release:

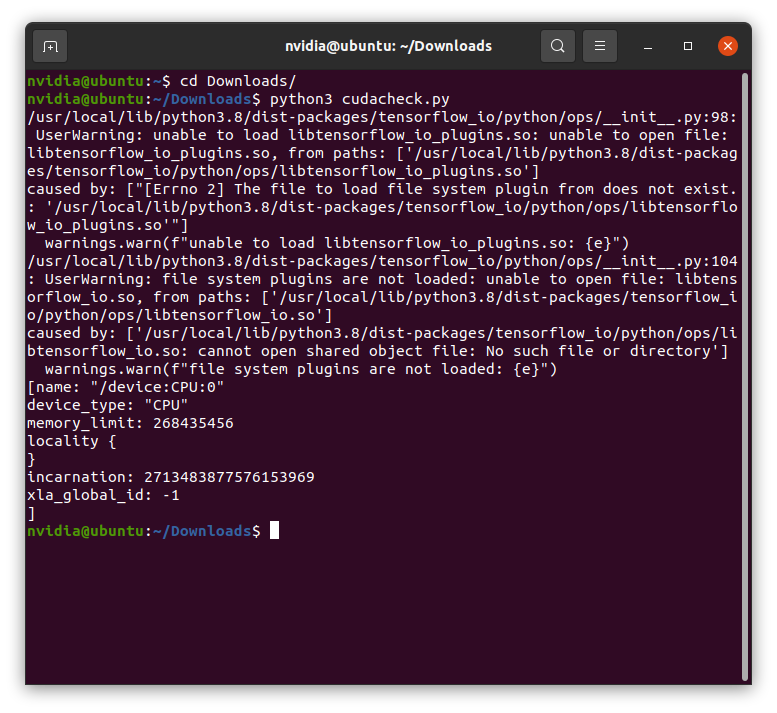
Yes! that is one of the lines within the script, here’s the screenshot and code of cudacheck.py :

from tensorflow.python.client import device_lib
import tensorflow
import os
import sys
#os.environ['TF_DETERMINISTIC_OPS'] = '1'
# os.environ['PYTHONHASHSEED'] = '0'
# os.environ['CUDA_VISIBLE_DEVICES']='1'
# os.environ['TF_CUDNN_USE_AUTOTUNE'] ='0'
#from keras import backend as K
#print(K._get_available_gpus())
print(device_lib.list_local_devices())
physical_devices = tensorflow.config.experimental.list_physical_devices('GPU')
print(physical_devices)
if physical_devices:
tensorflow.config.experimental.set_memory_growth(physical_devices[0], True)
print("Num GPUs Available: ", len(tensorflow.config.experimental.list_physical_devices('GPU')))
I’ve run the same script after setting everything up, every time I flashed, the first time I flashed I knew that there were mistakes made during the installation of tensorflow etc. but the second and third time, I did it in the prescribed way.
Please Help!
The project requirements that I have signed up for are on critical timelines and I have still not been able to set up the device for training, please do help me out.
I would like to request you to access my device remotely and do the required troubleshooting. Thanks in advance.
I’m sorry, I’m away on Thanksgiving holiday in the US - I will check if someone else can help you.
Hi,
Just double-check the l4t-tensorflow:r35.1.0-tf2.9-py3, GPU can be detected in our environment.
root@tegra-ubuntu:/# python3 cudacheck.py
2022-11-28 02:54:42.445313: I tensorflow/stream_executor/cuda/cuda_gpu_executor.cc:977] could not open file to read NUMA node: /sys/bus/pci/devices/0000:00:00.0/numa_node
Your kernel may have been built without NUMA support.
2022-11-28 02:54:42.496619: I tensorflow/stream_executor/cuda/cuda_gpu_executor.cc:977] could not open file to read NUMA node: /sys/bus/pci/devices/0000:00:00.0/numa_node
Your kernel may have been built without NUMA support.
2022-11-28 02:54:42.496953: I tensorflow/stream_executor/cuda/cuda_gpu_executor.cc:977] could not open file to read NUMA node: /sys/bus/pci/devices/0000:00:00.0/numa_node
Your kernel may have been built without NUMA support.
2022-11-28 02:54:43.195007: I tensorflow/stream_executor/cuda/cuda_gpu_executor.cc:977] could not open file to read NUMA node: /sys/bus/pci/devices/0000:00:00.0/numa_node
Your kernel may have been built without NUMA support.
2022-11-28 02:54:43.195406: I tensorflow/stream_executor/cuda/cuda_gpu_executor.cc:977] could not open file to read NUMA node: /sys/bus/pci/devices/0000:00:00.0/numa_node
Your kernel may have been built without NUMA support.
2022-11-28 02:54:43.195512: I tensorflow/core/common_runtime/gpu/gpu_device.cc:1616] Could not identify NUMA node of platform GPU id 0, defaulting to 0. Your kernel may not have been built with NUMA support.
2022-11-28 02:54:43.195681: I tensorflow/stream_executor/cuda/cuda_gpu_executor.cc:977] could not open file to read NUMA node: /sys/bus/pci/devices/0000:00:00.0/numa_node
Your kernel may have been built without NUMA support.
2022-11-28 02:54:43.195916: I tensorflow/core/common_runtime/gpu/gpu_device.cc:1532] Created device /device:GPU:0 with 24121 MB memory: -> device: 0, name: Orin, pci bus id: 0000:00:00.0, compute capability: 8.7
[name: "/device:CPU:0"
device_type: "CPU"
memory_limit: 268435456
locality {
}
incarnation: 5075951784676520715
xla_global_id: -1
, name: "/device:GPU:0"
device_type: "GPU"
memory_limit: 25293150720
locality {
bus_id: 1
links {
}
}
incarnation: 9194503349060694231
physical_device_desc: "device: 0, name: Orin, pci bus id: 0000:00:00.0, compute capability: 8.7"
xla_global_id: 416903419
]
2022-11-28 02:54:43.197277: I tensorflow/stream_executor/cuda/cuda_gpu_executor.cc:977] could not open file to read NUMA node: /sys/bus/pci/devices/0000:00:00.0/numa_node
Your kernel may have been built without NUMA support.
2022-11-28 02:54:43.197494: I tensorflow/stream_executor/cuda/cuda_gpu_executor.cc:977] could not open file to read NUMA node: /sys/bus/pci/devices/0000:00:00.0/numa_node
Your kernel may have been built without NUMA support.
2022-11-28 02:54:43.197667: I tensorflow/stream_executor/cuda/cuda_gpu_executor.cc:977] could not open file to read NUMA node: /sys/bus/pci/devices/0000:00:00.0/numa_node
Your kernel may have been built without NUMA support.
[PhysicalDevice(name='/physical_device:GPU:0', device_type='GPU')]
Num GPUs Available: 1
Based on your error “no cuda-capable device is detected”.
Could you check the /etc/nvidia-container-runtime/host-files-for-container.d/l4t.csv file?
In general, it should contain the below configuration that allows the GPU access within the container:
...
dev, /dev/nvhost-as-gpu
dev, /dev/nvhost-ctrl
dev, /dev/nvhost-ctrl-gpu
dev, /dev/nvhost-dbg-gpu
dev, /dev/nvhost-gpu
dev, /dev/nvhost-nvdec
dev, /dev/nvhost-nvdec1
dev, /dev/nvhost-prof-gpu
dev, /dev/nvhost-vic
dev, /dev/nvhost-ctrl-nvdla0
dev, /dev/nvhost-ctrl-nvdla1
dev, /dev/nvhost-nvdla0
dev, /dev/nvhost-nvdla1
dev, /dev/nvidiactl
...
Thanks.
This particular container was able to see the GPU! But it has a constant and obscure error whenever I try to import opencv-python, tried all the various options, uninstalling/reinstalling etc. Also there is not even a single search result on google that has documented this error.
import cv2
---------------------------------------------------------------------------
ImportError Traceback (most recent call last)
Cell In [3], line 1
----> 1 import cv2
File /usr/local/lib/python3.8/dist-packages/cv2/__init__.py:8
5 import importlib
6 import sys
----> 8 from .cv2 import *
9 from .cv2 import _registerMatType
10 from . import mat_wrapper
ImportError: libavcodec-e61fde82.so.58.134.100: cannot open shared object file: No such file or directory
l4t.csv (15.5 KB)
Here is the file that you asked me to locate, it has all the paths in place as you’ve mentioned.
It will be really helpful if it is possible for tensorflow to work at the host level rather than through the containers.
Also, If using containers is the way ahead, please help me resolve the opencv-python issue!
Please Help!
Thanks Again!
Hi,
You can install our prebuilt TensorFlow package with this document.
Please noted that a corresponding package version needs to be specified.
For example:
$ sudo pip3 install --extra-index-url https://developer.download.nvidia.com/compute/redist/jp/v502 tensorflow==2.10.0+nv22.11
It’s known that a third-party CPU package might be downloaded if not specify the package version.
Thanks.
1 Like
Yup I’ve already tried this as previously mentioned!
Tried this even after a fresh device flash to avoid any scope of mistakes, and I still face the same issue, ‘no GPU’ and the task at hand defaults to using the CPU.
I tried it again, and the GPU is now seen by tensorflow but now the same scikit-learn error is coming, as previously mentioned:
I’m also attaching the current output as well for reference:
nvidia@ubuntu:~/Downloads$ python3 mnist.py
/usr/local/lib/python3.8/dist-packages/tensorflow_io/python/ops/__init__.py:98: UserWarning: unable to load libtensorflow_io_plugins.so: unable to open file: libtensorflow_io_plugins.so, from paths: ['/usr/local/lib/python3.8/dist-packages/tensorflow_io/python/ops/libtensorflow_io_plugins.so']
caused by: ["[Errno 2] The file to load file system plugin from does not exist.: '/usr/local/lib/python3.8/dist-packages/tensorflow_io/python/ops/libtensorflow_io_plugins.so'"]
warnings.warn(f"unable to load libtensorflow_io_plugins.so: {e}")
/usr/local/lib/python3.8/dist-packages/tensorflow_io/python/ops/__init__.py:104: UserWarning: file system plugins are not loaded: unable to open file: libtensorflow_io.so, from paths: ['/usr/local/lib/python3.8/dist-packages/tensorflow_io/python/ops/libtensorflow_io.so']
caused by: ['/usr/local/lib/python3.8/dist-packages/tensorflow_io/python/ops/libtensorflow_io.so: cannot open shared object file: No such file or directory']
warnings.warn(f"file system plugins are not loaded: {e}")
Traceback (most recent call last):
File "/home/nvidia/.local/lib/python3.8/site-packages/sklearn/__check_build/__init__.py", line 48, in <module>
from ._check_build import check_build # noqa
ImportError: /home/nvidia/.local/lib/python3.8/site-packages/sklearn/__check_build/../../scikit_learn.libs/libgomp-d22c30c5.so.1.0.0: cannot allocate memory in static TLS block
During handling of the above exception, another exception occurred:
Traceback (most recent call last):
File "mnist.py", line 9, in <module>
import sklearn
File "/home/nvidia/.local/lib/python3.8/site-packages/sklearn/__init__.py", line 81, in <module>
from . import __check_build # noqa: F401
File "/home/nvidia/.local/lib/python3.8/site-packages/sklearn/__check_build/__init__.py", line 50, in <module>
raise_build_error(e)
File "/home/nvidia/.local/lib/python3.8/site-packages/sklearn/__check_build/__init__.py", line 31, in raise_build_error
raise ImportError(
ImportError: /home/nvidia/.local/lib/python3.8/site-packages/sklearn/__check_build/../../scikit_learn.libs/libgomp-d22c30c5.so.1.0.0: cannot allocate memory in static TLS block
___________________________________________________________________________
Contents of /home/nvidia/.local/lib/python3.8/site-packages/sklearn/__check_build:
__pycache__ setup.py _check_build.cpython-38-aarch64-linux-gnu.so
__init__.py
___________________________________________________________________________
It seems that scikit-learn has not been built correctly.
If you have installed scikit-learn from source, please do not forget
to build the package before using it: run `python setup.py install` or
`make` in the source directory.
If you have used an installer, please check that it is suited for your
Python version, your operating system and your platform.
Please help!
Can you try running export LD_PRELOAD=/home/nvidia/.local/lib/python3.8/site-packages/sklearn/__check_build/../../scikit_learn.libs/libgomp-d22c30c5.so.1.0.0 before you run your python script?
1 Like
My Issue has been solved, I’m using the above mentioned TensorFlow version and since I needed torch version ‘1.10.0’ I had to build the wheel file from source which all worked out, thanks to @dusty_nv for managing all those intricate patches that I had to do by hand, which just worked out in the end (even for the architecture version ‘8.7’ as I’m on the AGX Orin) also thanking @AastaLLL as the version you suggested worked without any flaws.
This topic was automatically closed 14 days after the last reply. New replies are no longer allowed.