I’m currently working with an RTX 5080 (Blackwell) device and have successfully set up a Triton Inference Server with the CUDA Toolkit installed. I’m using it primarily to run nvOCDR, and so far, everything works smoothly for both image and video inputs when tested manually.
However, when running video inference directly through Triton, I’ve noticed a significant performance bottleneck—particularly due to limited batch size handling in the current nvOCDR setup. From what I’ve observed, this greatly impacts real-time performance.
After reading through previous discussions, I came across a suggestion that:
I’d like to know:
Has anyone here deployed DeepStream with Triton backend on RTX 5080 or similar (5090)?
Can this integration overcome the batch size limitation observed with standalone Triton + nvOCDR?
Are there sample pipelines or configuration templates for DeepStream + Triton specifically optimized for Blackwell GPUs?
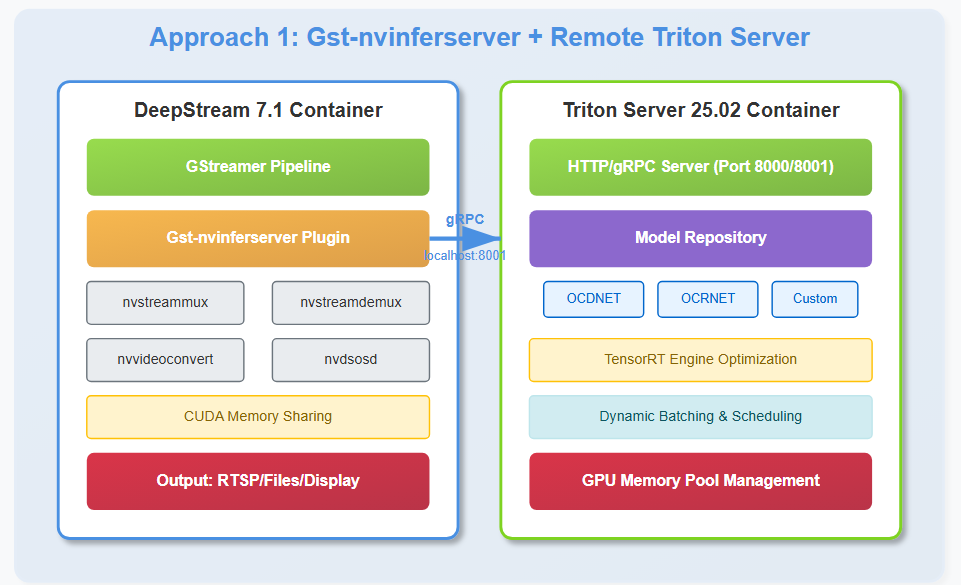
I didn’t use OCDNet in this example - you’ll need to implement the text detection model in Triton as well if you want full text processing. In my example, I just deploy OCRNet as primary inference, but if you want to detect text, you can use OCDNet as primary inference and OCRNet as secondary inference.
Thank you for your helpful advice
You mentioned that “DeepStream can work with Blackwell GPUs when using the Triton Inference Server as a backend instead of the native inference engine.” That caught my attention, and I’d like to understand how to make that work.
Currently, I have successfully deployed Triton Inference Server running both OCDNet and OCRNet models. However, I want to integrate this setup into DeepStream. The challenge is that I’m using a Blackwell GPU (RTX 5080), which is not supported by the default DeepStream inference engine.
I’ve already built and successfully deployed Triton Inference Server (v25.01/25.02) with two optimized TensorRT models: OCDNet and OCRNet. So basically, I probably just need to build DeepStream 7.1 inside a container, but I’m still unsure because most of the specifications in the documentation don’t match my PC.
Now, I’d like to clarify a few things regarding the DeepStream 7.1 container setup:
Since I only have one GPU (RTX 5080) 16GB, which is currently dedicated to running the Triton Server, is it still possible to use the same GPU for the DeepStream 7.1 container as well?I understand that DeepStream requires CUDA memory sharing and GPU access even if inference is performed remotely via gst-nvinferserver. My concern is whether both DeepStream and Triton can share the same GPU without conflict, or if a separate GPU is mandatory.
Could you provide the correct installation method or Docker image for DeepStream 7.1 Container that supports RTX 5080?Based on the official documentation, the required environment for RTX GPUs includes:
Q1: Can share the same GPU
Q2: DeepStream can be deployed the same way as on any other GPU.
The only restriction is not use gst-nvinfer but use gst-nvinferserver.
docker run \
-it \
--net=host \
--ipc=host \
--gpus all \
nvcr.io/nvidia/deepstream:7.1-triton-multiarch
Thank you so much!
I’ll run the DeepStream Docker container as per your guidance.
By the way, I’m already running Triton Inference using a separate Docker container, so I believe this setup is safe and won’t interfere with other configurations.
Also my Triton Server is running version 25.01. I’ll try testing the integration between DeepStream and Triton using this version first.
If it doesn’t work properly, I’ll rebuild Triton Server using version 25.02 as recommended.