WARNING: [TRT]: onnx2trt_utils.cpp:366: Your ONNX model has been generated with INT64 weights, while TensorRT does not natively support INT64. Attempting to cast down to INT32.
Are there any solutions to work around this to improve the model accuracy?
This is a gap between ONNX and TensorRT. The weight value is rarely larger than 32 bits integer. This warning can be ignored, no accuracy issue with this warning.
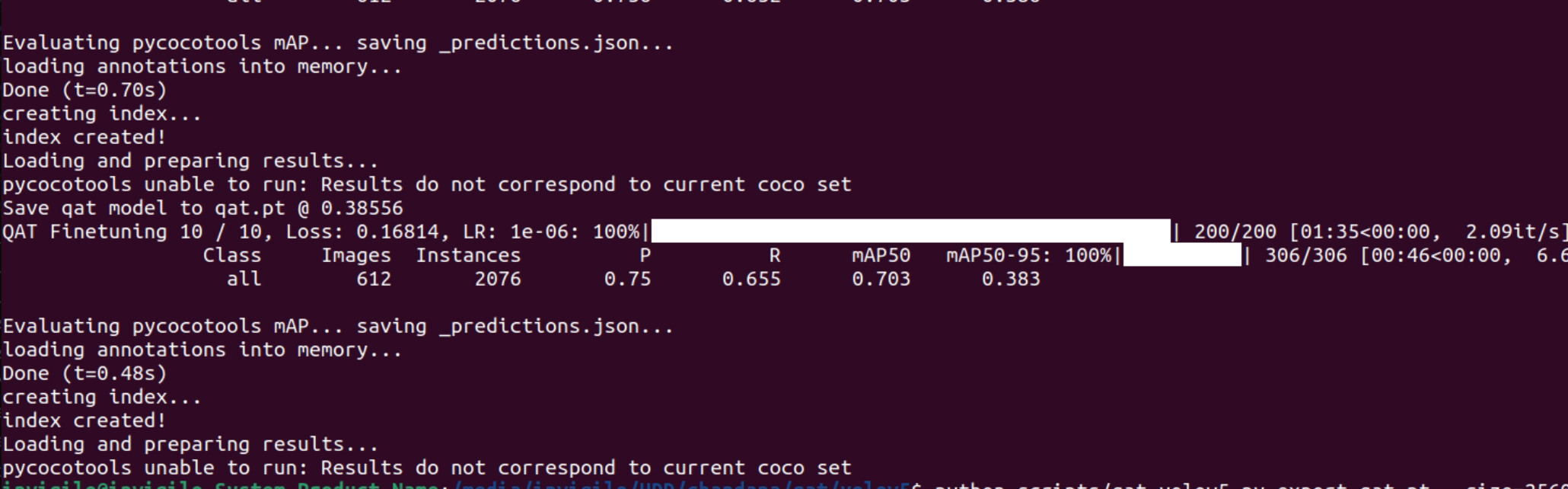
I followed https://github.com/NVIDIA-AI-IOT/yolo_deepstream/tree/main/yolov7_qat and somehow lost all the detections that I was previously getting. I used the qat.onnx one, what could possibly be going wrong here? i was getting this issue while running the quantize command, is that going to affect anything? @Fiona.Chen
I didn’t use any metric as such, I just ran inference using different models on the same video and looked at it and saw the difference, quite possible the issue is something else
this is the inference using detect.py from ultralytics’ yolov5 repo (.pt weights) External Image
this is the video i saved from the deepstream app using onnx model which was converted into .engine file (FP16) External Image
you can see that the person hardly gets detected for the second half of the video, what could be the reason behind it?
There is no update from you for a period, assuming this is not an issue anymore. Hence we are closing this topic. If need further support, please open a new one. Thanks
They are open source. You can check and implement by yourself.