Hello,
I am trying to analyze a network inference (YoloV4 with 608x608 input size) by using nsys on Jetson AGX platform. I utilize cuda allocators, new stream, context, enqueue and Async memCopies etc. I need to optimize run time but I cannot understand the number of calls for certain methods and I don’t understand the run times of certain methods. I tried two runs with explicit synchronization calls and without them. I have separate questions for both.
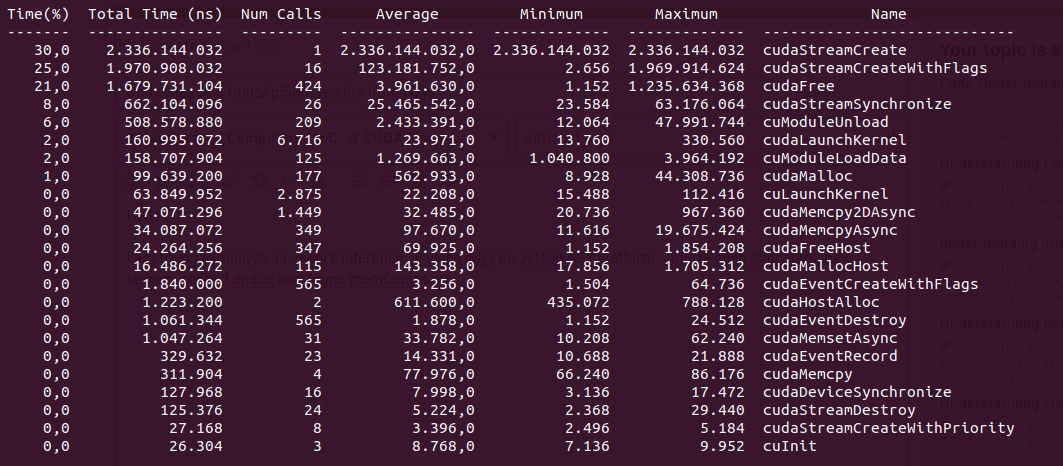
Figure1: NSYS results for 23 frames with cudaStreamSynchronize() after every frame
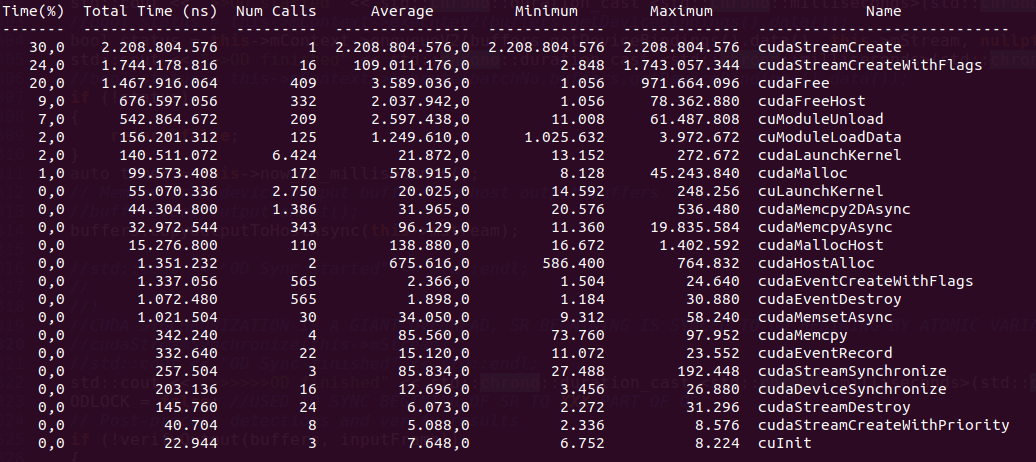
Figure2: NSYS results for 22 frames without cudaStreamSynchronize()
My code is as follows in psuedo form
in Main()
create a std::thread for network_infer_fnc(), pass input and output cv::Mats.
read the video frame by frame
in network_infer_fnc()
create inference class, initialize params
call class.builder(), which reads .engine file, sets flags, creates a stream with cudaStreamCreate(), creates Execution Context
in a loop controlled by Main
call class.infer()
create buffers with cudaMalloc/cudaFree cudaMallocHost/cudaFreeHost
class.processInput() -> pass input pixels to host buffer
cudaMemcpyAsync() to pass host buffer to device
context.enqueueV2()
cudaMemcpyAsync() to read device output buffer into host
cudaStreamSynchronize()
class.processOutputs()
return;
cv::imshow(output)
Questions:
- On Figure 1 Why cudaStreamSynchronize() takes 25ms on average? How can I reduce it?
-
On Figure 1 What is cudaStreamCreateWithFlags(), why is it there? And why is it taking whopping 123ms on average? How can I get rid of it?This seems to be one time thing, so I delete the question. - On Figure 1 Why is there 26 calls to cudaStreamSynchronize() whereas I called the infer method 23 times? What might be the cause of extra calls?
- On Figure 1 Why is there 424 cudaFree, 177 cudaMalloc, 347 cudaFreeHost, 115 cudaMallocHost calls? Shouldn’t it be the number of times I call buffer creation which is 23 times.
- On Figure 1 Why is it taking 3.96 ms on average to call cudaFree()? how can I reduce it?
- On Figure 2 it seems the Synchronization overhead is gone to cudaFreeHost()? I tried to heed the advice described in Problem6: Excessive Synchronziation here Do I need to start and finish the processing and outputting of entire video sequence inside the same method to prevent certain deconstructors calling implicit synchronization? Or what else should I do? The linked presentation falls short on suggesting a working solution.
That’s a lot of questions. I’d be glad even if you could answer some of them. I think I am not using network inference with high efficiency and I want to know the tricks to improve it.
Thanks in advance,
Cem