Hello everyone,
We are having issues with an A30 GPU card installed on our server. The specs of our system are the following:
- Intel(R) Xeon(R) Gold 5218R CPU @ 2.10GHz with 126GB of RAM
- Linux kernel: 5.4.0-121-generic
- 1x NVIDIA A30
- 1x Tesla V100
- CUDA version: 11.7 / Driver Version: 515.48.07
- NVCC version: 11.7
We have blacklisted nouveau drivers, both within grub and in /etc/modprobe.d/blacklist-nvidia-nouveau.conf.
The system was working properly up until last week, but after then the A30 is not able to run any kernel. We have re-installed all the drivers but the issue was not fixed. nvidia-smi is recognizing the card, as shown below:

However, A30 is not able to launch any kernel. What we have tested:
Run a simple kernel (matrix-mul from the following repo GitHub - kberkay/Cuda-Matrix-Multiplication: Matrix Multiplication on GPU using Shared Memory considering Coalescing and Bank Conflicts) on both A30 and V100 (code also attached)
mm.cu (8.2 KB)
On V100 the application is executed successfully as you can see below:
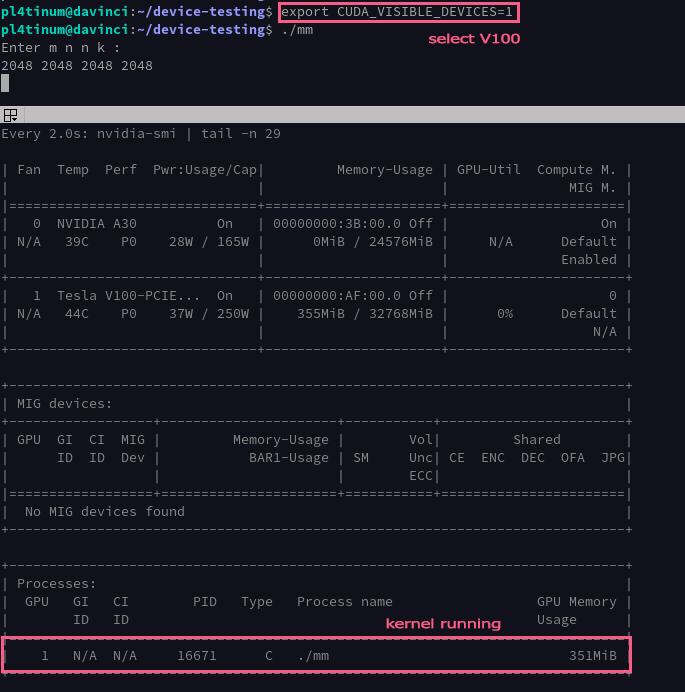
After the completion of the kernel we get a success message:
GPU time= 5.651456 ms
CPU time= 76829.059000 ms
Results are equal!
On V100 the same kernel does not run on the GPU:

Moreover, we get the following output:
GPU time= -0.000000 ms
CPU time= 75701.587000 ms
NOT EQUAL
Results are NOT equal!
showing that the GPU did not perform any execution.
dmesg messages regarding nvidia and NVRM are the following:
nvidia:
pl4tinum@davinci:~$ dmesg | grep nvidia
[ 3.207155] nvidia: loading out-of-tree module taints kernel.
[ 3.207169] nvidia: module license 'NVIDIA' taints kernel.
[ 3.244573] nvidia: module verification failed: signature and/or required key missing - tainting kernel
[ 3.252388] nvidia-nvlink: Nvlink Core is being initialized, major device number 239
[ 3.379058] nvidia-modeset: Loading NVIDIA Kernel Mode Setting Driver for UNIX platforms 515.48.07 Fri May 27 03:18:00 UTC 2022
[ 3.714251] [drm] [nvidia-drm] [GPU ID 0x00003b00] Loading driver
[ 5.999727] [drm] Initialized nvidia-drm 0.0.0 20160202 for 0000:3b:00.0 on minor 1
[ 5.999802] [drm] [nvidia-drm] [GPU ID 0x0000af00] Loading driver
[ 6.942172] [drm] Initialized nvidia-drm 0.0.0 20160202 for 0000:af:00.0 on minor 2
[ 8.597268] nvidia-uvm: Loaded the UVM driver, major device number 236.
[ 29.563178] audit: type=1400 audit(1657361126.061:3): apparmor="STATUS" operation="profile_load" profile="unconfined" name="nvidia_modprobe" pid=1711 comm="apparmor_parser"
[ 29.563181] audit: type=1400 audit(1657361126.061:4): apparmor="STATUS" operation="profile_load" profile="unconfined" name="nvidia_modprobe//kmod" pid=1711 comm="apparmor_parser"
NVRM:
[ 3.346856] NVRM: loading NVIDIA UNIX x86_64 Kernel Module 515.48.07 Fri May 27 03:26:43 UTC 2022
We have also tested running GPU-accelerated NN layers from Pytorch and we get the following message:
/usr/local/lib/python3.8/dist-packages/torch/cuda/__init__.py:83: UserWarning: CUDA initialization: CUDA driver initialization failed, you might not have a CUDA gpu. (Triggered internally at ../c10/cuda/CUDAFunctions.cpp:109.)
return torch._C._cuda_getDeviceCount() > 0
I am also attaching the file produced by nvidia-bug-report.sh script.
nvidia-bug-report.log.gz (15.1 MB)
Could this be a HW malfunction or something else?
Thanks in advance for your help!