thanks ,run $ sudo jetson_clocks it’s work;
but I have anther question,
I’m trying VLM by ollama, base on the web" Tags · qwen2.5vl ", we can try ollama server + webUI + qwen2.5vl;
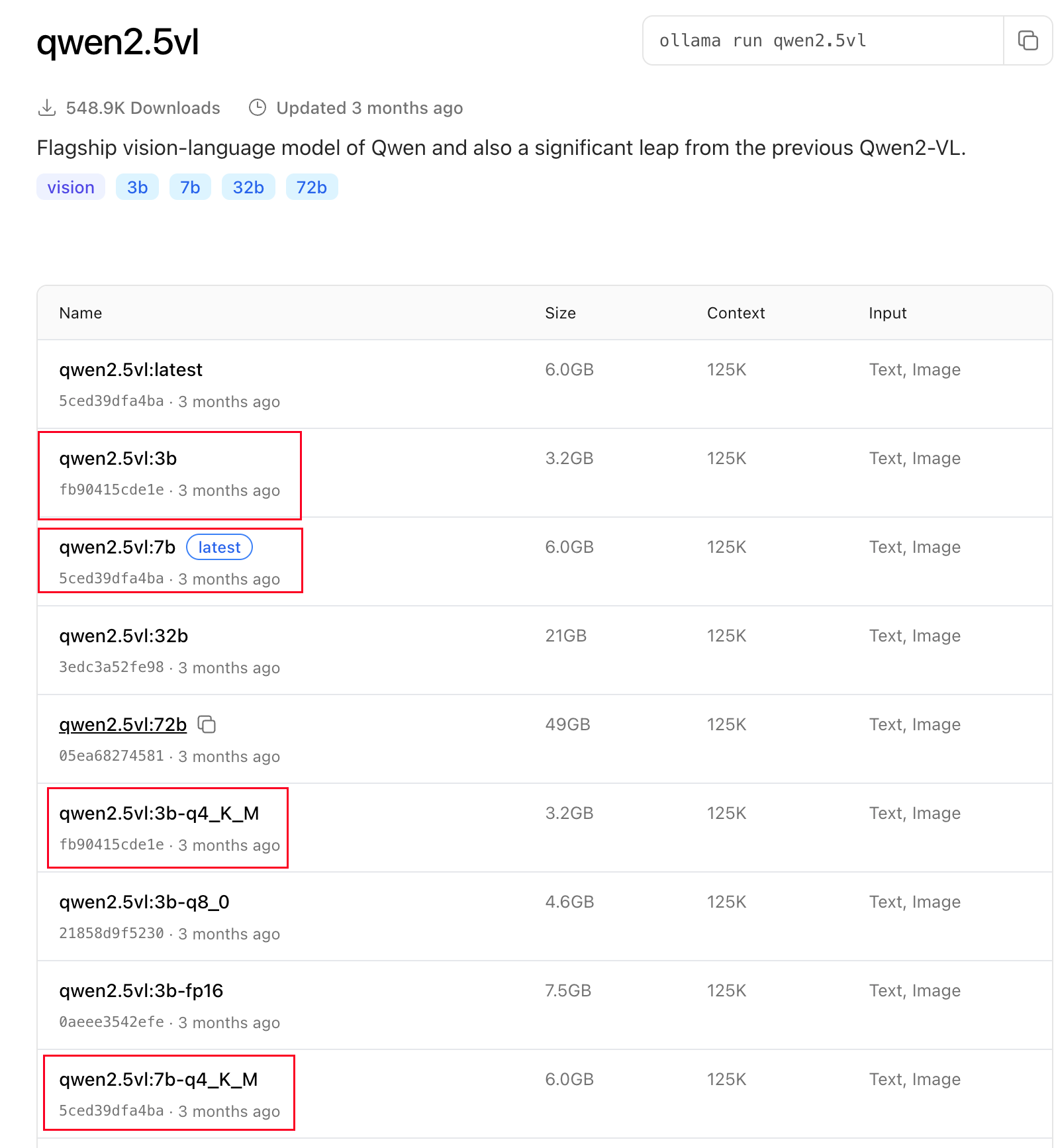
1、 Install the ollama server, the cmd is:
curl-fsSL https://ollama.com/install.sh / sh
sudo systemctl start ollama

2、 Install Open WebUI base by docker:
docker run -d
–name open-webui
-p 3000:8080
-e OLLAMA_API_BASE_URL=http://host.docker.internal:11434
-v /var/run/docker.sock:/var/run/docker.sock
–gpus all
ghcr.io/open-webui/open-webui:main
3、 start the VLM experiment
a、download the model: ollama run qwen2.5vl:3b
b、vim Modelfile:
FROM qwen2.5vl:3b
PARAMETER num_ctx 512
PARAMETER num_gpu 1
PARAMETER temperature 0.7
SYSTEM “你是一个支持中文的多模态 AI 助手”
c、run: ollama create qwen2.5vl:3b -f Modelfile
d、test:ollama run qwen2.5vl:3b “你好”
but, the result is:

if I modify the Modelfile as: PARAMETER num_gpu 1 ----> 0, it's work,

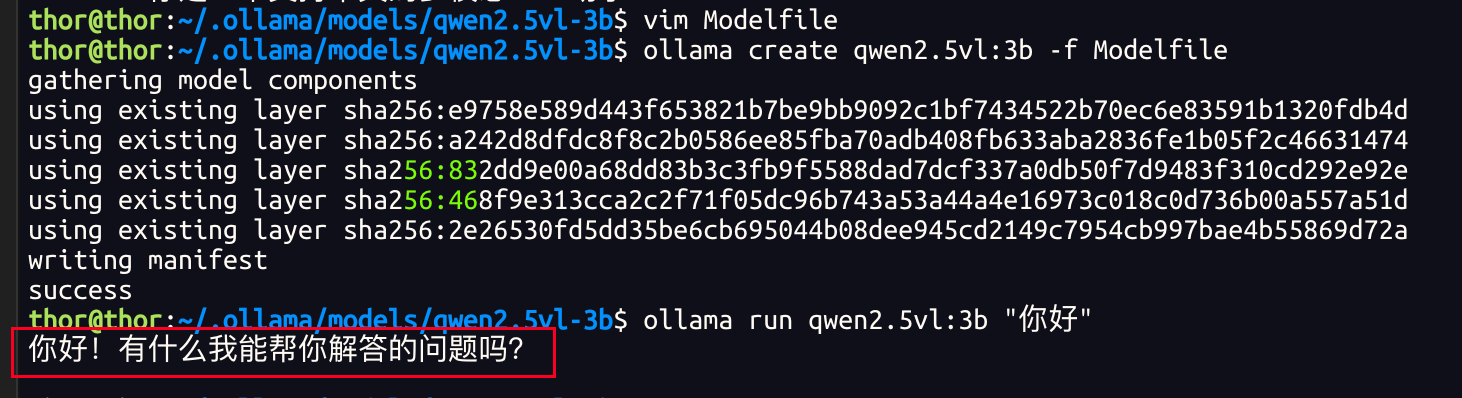
but it’s not I wanted, it’s working on cpu, not GPU

Please help me confirm what is wrong with my environment, thanks;