Matrix multiplication needs to read/write memory frequently and might be impacted by the memory bandwidth.
Please find the Thor benchmark results below:
An example to reproduce the LLM perf is shared in the topic below:
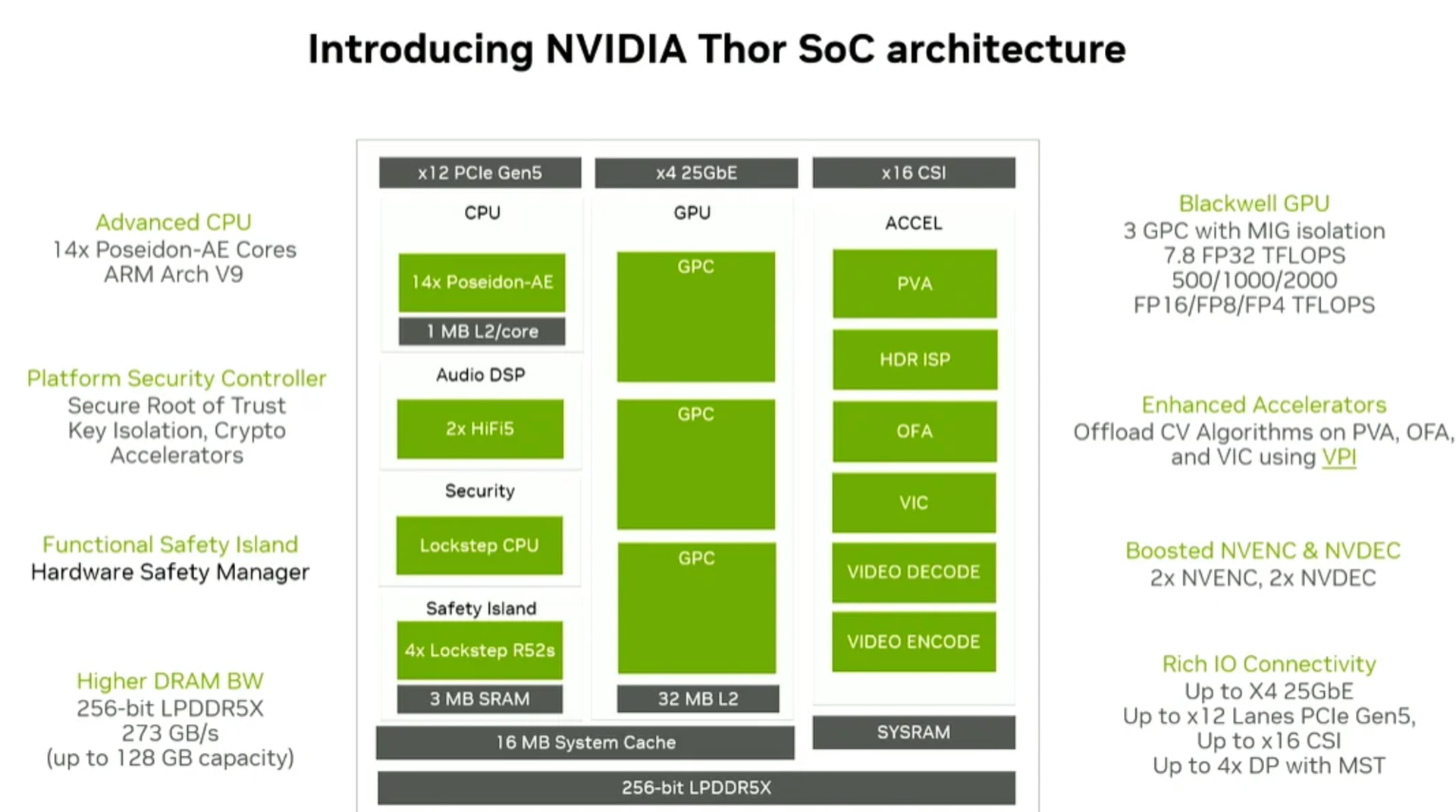
Sorry I didn’t see any TFLOPs data in the data sheet. I read this from the keynote from nvidia in reddit release here: Reddit - The heart of the internet.
I think the 500 / 1000 / 2000 TFLOPs for fp16, fp8 and fp4 are tensor core performances.
Could you plz confirm that the 7.8 TFLOPs is for cuda core or tensor core for FP32? If it’s for cuda core, what’s the tensor core performance for FP32?
I tried a simple CuBLAS GeMM on 4090 and it can saturate the claimed tensor core TFLOPS (280 / 330 TFLOPs) easily. Why is it hard on Thor? Is there a standard way to get the expected performance (500 TFLOPs, I can only get ~130 TFLOPs) on it?
Please download the “Jetson T5000 Series Modules Data Sheet” file and you can find the information on page 1.
7.096 FP32 TFLOPs is the performance of CUDA cores.
Tensor Core (fifth-generation) supports TensorFloat-32 (TF32), bfloat16, FP16, FP8, FP4, and INT8.
It doesn’t support FP32.