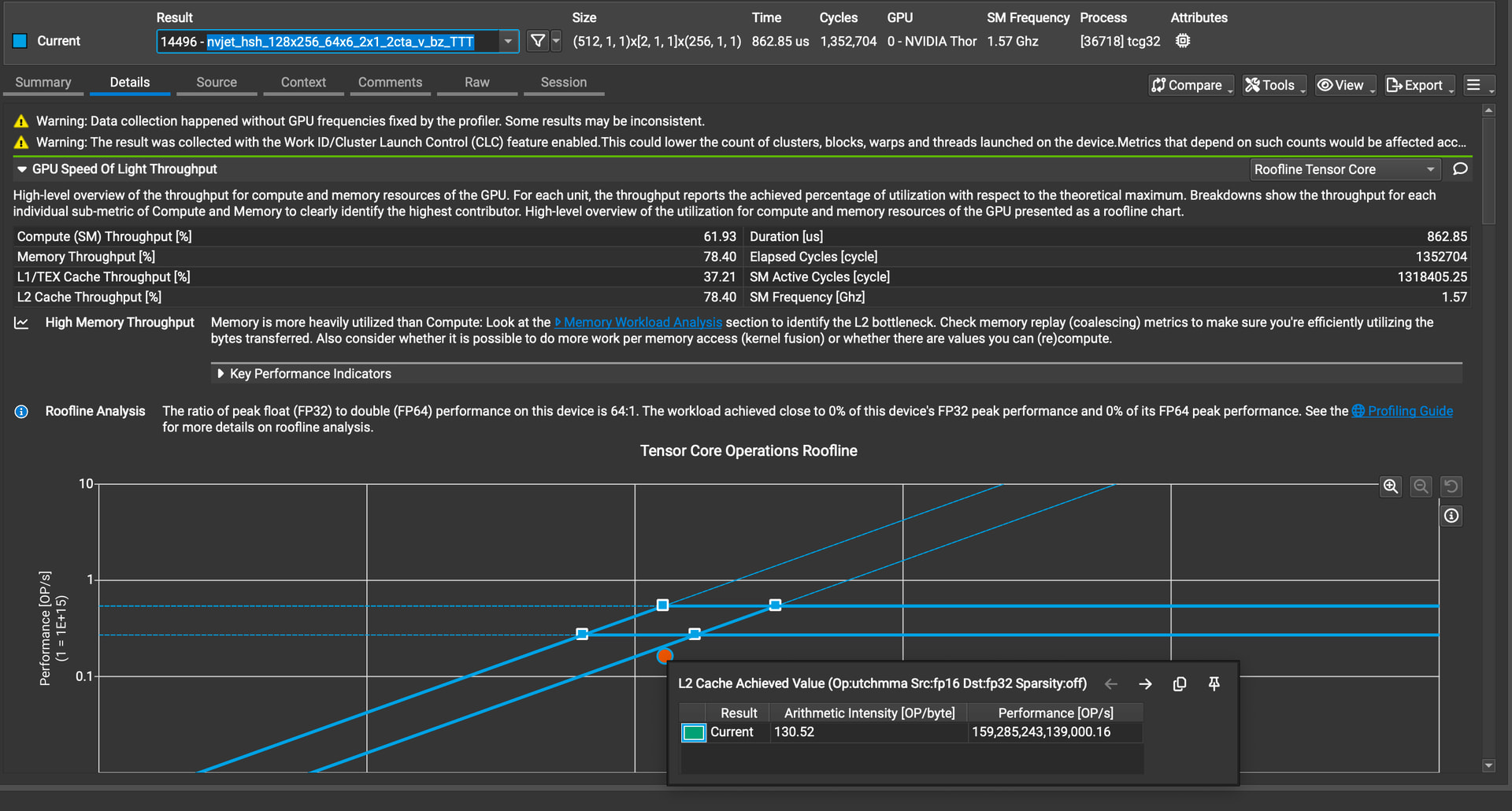
Thanks for replying.
Yes, the results are using the same script only changing the cuBLAS option from CUBLAS_COMPUTE_16F to CUBLAS_COMPUTE_32F.
Here’s the script I used
// tc_gemm_fp16_acc16.cu
// Tensor Core FP16 GEMM benchmark using cuBLAS with **FP16 accumulation**.
//
// Build:
// nvcc -O3 -std=c++17 tc_gemm_fp16_acc16.cu -o tc_gemm_fp16_acc16 -lcublas
//
// Run examples:
// ./tc_gemm_fp16_acc16 --m=4096 --n=4096 --k=4096 --iters=200 --warmup=20
//
// Notes:
// - FP16 inputs/outputs with FP16 accumulation (CUBLAS_COMPUTE_16F).
// - Requests Tensor Cores via CUBLAS_GEMM_DEFAULT_TENSOR_OP and TENSOR_OP_MATH.
// - TFLOP/s = (2*M*N*K * iters) / elapsed_time / 1e12.
// - Sizes that are multiples of 128/256 often map best to TC tiles.
#include <cuda_runtime.h>
#include <cublas_v2.h>
#include <cstdio>
#include <cstdlib>
#include <cstring>
#include <string>
#include <iostream>
#include <iomanip>
#include <cuda_fp16.h>
#define CUDA_CHECK(call) do { \
cudaError_t err = (call); \
if (err != cudaSuccess) { \
fprintf(stderr, "CUDA error %s:%d: %s\n", __FILE__, __LINE__, cudaGetErrorString(err)); \
std::exit(EXIT_FAILURE); \
} \
} while (0)
#define CUBLAS_CHECK(call) do { \
cublasStatus_t st = (call); \
if (st != CUBLAS_STATUS_SUCCESS) { \
fprintf(stderr, "cuBLAS error %s:%d: status %d\n", __FILE__, __LINE__, (int)st); \
std::exit(EXIT_FAILURE); \
} \
} while (0)
struct Args {
int m = 8192, n = 8192, k = 8192;
int iters = 200;
int warmup = 20;
bool column_major = false; // default: treat buffers as row-major and use transpose trick
};
Args parse(int argc, char** argv) {
Args a;
for (int i=1;i<argc;++i) {
std::string s(argv[i]);
auto val = [&](const char* k)->const char* {
if (s.rfind(k,0)==0) { const char* p = s.c_str()+strlen(k); if (*p=='=') ++p; return p; }
return nullptr;
};
if (s=="--help"||s=="-h") {
std::cout << "Usage: " << argv[0]
<< " [--m=M] [--n=N] [--k=K] [--iters=N] [--warmup=N] [--colmajor]\n";
std::exit(0);
}
if (s.rfind("--m",0)==0) a.m = std::stoi(val("--m"));
else if (s.rfind("--n",0)==0) a.n = std::stoi(val("--n"));
else if (s.rfind("--k",0)==0) a.k = std::stoi(val("--k"));
else if (s.rfind("--iters",0)==0) a.iters = std::stoi(val("--iters"));
else if (s.rfind("--warmup",0)==0) a.warmup = std::stoi(val("--warmup"));
else if (s=="--colmajor") a.column_major = true;
}
return a;
}
// Initialize FP16 buffer with pseudo-random values (GPU-side)
__global__ void init_half(__half* data, size_t n, unsigned long long seed) {
size_t i = blockIdx.x * blockDim.x + threadIdx.x;
if (i < n) {
unsigned long long x = seed ^ (1469598103934665603ull + i*1099511628211ull);
x ^= x >> 12; x ^= x << 25; x ^= x >> 27;
float f = (float)(x & 0xFFFF) / 65535.0f - 0.5f; // [-0.5,0.5]
data[i] = __float2half(f);
}
}
int main(int argc, char** argv) {
Args a = parse(argc, argv);
int dev=0; CUDA_CHECK(cudaGetDevice(&dev));
cudaDeviceProp prop{}; CUDA_CHECK(cudaGetDeviceProperties(&prop, dev));
std::cout << "Device: " << prop.name << "\n";
std::cout << "GEMM size: M=" << a.m << " N=" << a.n << " K=" << a.k << "\n";
std::cout << "Iters: " << a.iters << " Warmup: " << a.warmup << "\n";
const size_t elemsA = (size_t)a.m * a.k;
const size_t elemsB = (size_t)a.k * a.n;
const size_t elemsC = (size_t)a.m * a.n;
__half* dA=nullptr; __half* dB=nullptr; __half* dC=nullptr;
CUDA_CHECK(cudaMalloc(&dA, elemsA * sizeof(__half)));
CUDA_CHECK(cudaMalloc(&dB, elemsB * sizeof(__half)));
CUDA_CHECK(cudaMalloc(&dC, elemsC * sizeof(__half)));
// Initialize A,B; zero C
{
dim3 blk(256);
dim3 grdA((unsigned)((elemsA + blk.x - 1) / blk.x));
dim3 grdB((unsigned)((elemsB + blk.x - 1) / blk.x));
init_half<<<grdA, blk>>>(dA, elemsA, 0xA5A5A5A5ull);
init_half<<<grdB, blk>>>(dB, elemsB, 0x5A5A5A5Aull);
CUDA_CHECK(cudaMemset(dC, 0, elemsC * sizeof(__half)));
CUDA_CHECK(cudaDeviceSynchronize());
}
cublasHandle_t handle; CUBLAS_CHECK(cublasCreate(&handle));
CUBLAS_CHECK(cublasSetMathMode(handle, CUBLAS_TENSOR_OP_MATH));
// Scalars in FP16 (compute=16F requires alpha/beta as FP16)
__half alpha = __float2half(1.0f);
__half beta = __float2half(0.0f);
// Layout handling (cuBLAS is column-major)
cublasOperation_t opA = CUBLAS_OP_N, opB = CUBLAS_OP_N;
int lda, ldb, ldc;
int m, n, k;
if (a.column_major) {
m = a.m; n = a.n; k = a.k;
lda = a.m; ldb = a.k; ldc = a.m;
opA = CUBLAS_OP_N; opB = CUBLAS_OP_N;
} else {
// Row-major buffers: compute C^T = B^T * A^T
m = a.n; n = a.m; k = a.k; // swap m<->n
lda = a.k; ldb = a.n; ldc = a.n;
opA = CUBLAS_OP_T; opB = CUBLAS_OP_T;
}
// Warm-up
for (int w=0; w<a.warmup; ++w) {
CUBLAS_CHECK(cublasGemmEx(
handle,
opB, opA,
m, n, k,
&alpha,
dB, CUDA_R_16F, ldb,
dA, CUDA_R_16F, lda,
&beta,
dC, CUDA_R_16F, ldc,
CUBLAS_COMPUTE_16F, CUBLAS_GEMM_DEFAULT_TENSOR_OP));
}
CUDA_CHECK(cudaDeviceSynchronize());
// Timed loop
cudaEvent_t start, stop;
CUDA_CHECK(cudaEventCreate(&start));
CUDA_CHECK(cudaEventCreate(&stop));
CUDA_CHECK(cudaEventRecord(start));
for (int it=0; it<a.iters; ++it) {
CUBLAS_CHECK(cublasGemmEx(
handle,
opB, opA,
m, n, k,
&alpha,
dB, CUDA_R_16F, ldb,
dA, CUDA_R_16F, lda,
&beta,
dC, CUDA_R_16F, ldc,
CUBLAS_COMPUTE_16F, CUBLAS_GEMM_DEFAULT_TENSOR_OP));
}
CUDA_CHECK(cudaEventRecord(stop));
CUDA_CHECK(cudaEventSynchronize(stop));
float ms=0.0f;
CUDA_CHECK(cudaEventElapsedTime(&ms, start, stop));
double seconds = ms / 1e3;
// FLOPs per GEMM = 2*M*N*K (FMA = 2 operations)
const double flops_per = 2.0 * (double)a.m * (double)a.n * (double)a.k;
const double total_flops = flops_per * (double)a.iters;
const double tflops = total_flops / seconds / 1e12;
std::cout << std::fixed << std::setprecision(2);
std::cout << "Elapsed: " << ms << " ms for " << a.iters << " GEMMs\n";
std::cout << "Throughput: " << tflops << " TFLOP/s (FP16 inputs, FP16 accumulate, TC)\n";
// Cleanup
CUDA_CHECK(cudaEventDestroy(start)); CUDA_CHECK(cudaEventDestroy(stop));
CUBLAS_CHECK(cublasDestroy(handle));
cudaFree(dA); cudaFree(dB); cudaFree(dC);
return 0;
}