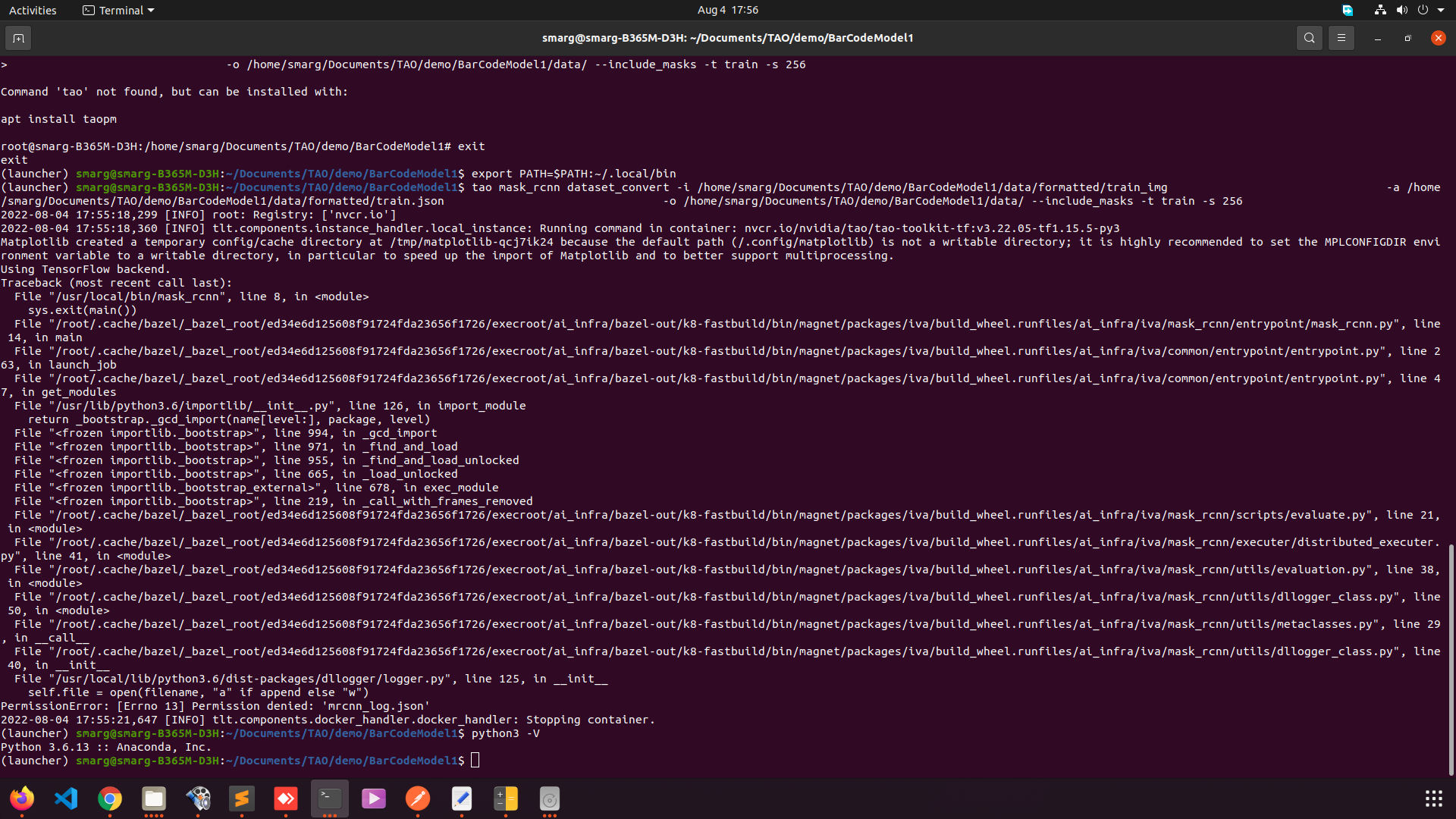
Hi @Morganh
I am able to run mask_rcnn train successfully but logs showing loss 0.00000 fast_rcnn class loss: 0.00000 fast_rcnn box loss: 0.00000
Training Logs:
For multi-GPU, change --gpus based on your machine.
2022-08-05 16:20:43,606 [INFO] root: Registry: ['nvcr.io']
2022-08-05 16:20:43,666 [INFO] tlt.components.instance_handler.local_instance: Running command in container: nvcr.io/nvidia/tao/tao-toolkit-tf:v3.22.05-tf1.15.5-py3
2022-08-05 16:20:43,701 [WARNING] tlt.components.docker_handler.docker_handler:
Docker will run the commands as root. If you would like to retain your
local host permissions, please add the "user":"UID:GID" in the
DockerOptions portion of the "/home/smarg/.tao_mounts.json" file. You can obtain your
users UID and GID by using the "id -u" and "id -g" commands on the
terminal.
Using TensorFlow backend.
WARNING:tensorflow:Deprecation warnings have been disabled. Set TF_ENABLE_DEPRECATION_WARNINGS=1 to re-enable them.
/usr/local/lib/python3.6/dist-packages/requests/__init__.py:91: RequestsDependencyWarning: urllib3 (1.26.5) or chardet (3.0.4) doesn't match a supported version!
RequestsDependencyWarning)
Using TensorFlow backend.
[INFO] Loading specification from /workspace/tao-experiments/mask_rcnn/specs/maskrcnn_train_resnet10.txt
[MaskRCNN] INFO : Loading weights from /workspace/tao-experiments/mask_rcnn/experiment_dir_unpruned/model.step-0.tlt
[MaskRCNN] INFO : Loading weights from /workspace/tao-experiments/mask_rcnn/experiment_dir_unpruned/model.step-0.tlt
[INFO] Log file already exists at /workspace/tao-experiments/mask_rcnn/experiment_dir_unpruned/status.json
[INFO] Starting MaskRCNN training.
INFO:tensorflow:Using config: {'_model_dir': '/tmp/tmpdd62oueg', '_tf_random_seed': 123, '_save_summary_steps': None, '_save_checkpoints_steps': None, '_save_checkpoints_secs': None, '_session_config': intra_op_parallelism_threads: 1
inter_op_parallelism_threads: 4
gpu_options {
allow_growth: true
force_gpu_compatible: true
}
allow_soft_placement: true
graph_options {
rewrite_options {
meta_optimizer_iterations: TWO
}
}
, '_keep_checkpoint_max': 20, '_keep_checkpoint_every_n_hours': None, '_log_step_count_steps': None, '_train_distribute': None, '_device_fn': None, '_protocol': None, '_eval_distribute': None, '_experimental_distribute': None, '_experimental_max_worker_delay_secs': None, '_session_creation_timeout_secs': 7200, '_service': None, '_cluster_spec': <tensorflow.python.training.server_lib.ClusterSpec object at 0x7fc72c0ca828>, '_task_type': 'worker', '_task_id': 0, '_global_id_in_cluster': 0, '_master': '', '_evaluation_master': '', '_is_chief': True, '_num_ps_replicas': 0, '_num_worker_replicas': 1}
[MaskRCNN] INFO : Create EncryptCheckpointSaverHook.
[MaskRCNN] INFO : =================================
[MaskRCNN] INFO : Start training cycle 01
[MaskRCNN] INFO : =================================
WARNING:tensorflow:Entity <function InputReader.__call__.<locals>._prefetch_dataset at 0x7fc72c0c7bf8> could not be transformed and will be executed as-is. Please report this to the AutoGraph team. When filing the bug, set the verbosity to 10 (on Linux, `export AUTOGRAPH_VERBOSITY=10`) and attach the full output. Cause: Unable to locate the source code of <function InputReader.__call__.<locals>._prefetch_dataset at 0x7fc72c0c7bf8>. Note that functions defined in certain environments, like the interactive Python shell do not expose their source code. If that is the case, you should to define them in a .py source file. If you are certain the code is graph-compatible, wrap the call using @tf.autograph.do_not_convert. Original error: could not get source code
WARNING:tensorflow:From /opt/nvidia/third_party/keras/tensorflow_backend.py:349: The name tf.get_default_graph is deprecated. Please use tf.compat.v1.get_default_graph instead.
WARNING:tensorflow:From /usr/local/lib/python3.6/dist-packages/tensorflow_core/python/autograph/converters/directives.py:119: The name tf.set_random_seed is deprecated. Please use tf.compat.v1.set_random_seed instead.
WARNING:tensorflow:Entity <function dataset_parser at 0x7fc737a6da60> could not be transformed and will be executed as-is. Please report this to the AutoGraph team. When filing the bug, set the verbosity to 10 (on Linux, `export AUTOGRAPH_VERBOSITY=10`) and attach the full output. Cause: Unable to locate the source code of <function dataset_parser at 0x7fc737a6da60>. Note that functions defined in certain environments, like the interactive Python shell do not expose their source code. If that is the case, you should to define them in a .py source file. If you are certain the code is graph-compatible, wrap the call using @tf.autograph.do_not_convert. Original error: could not get source code
WARNING:tensorflow:The operation `tf.image.convert_image_dtype` will be skipped since the input and output dtypes are identical.
WARNING:tensorflow:The operation `tf.image.convert_image_dtype` will be skipped since the input and output dtypes are identical.
WARNING:tensorflow:The operation `tf.image.convert_image_dtype` will be skipped since the input and output dtypes are identical.
WARNING:tensorflow:The operation `tf.image.convert_image_dtype` will be skipped since the input and output dtypes are identical.
INFO:tensorflow:Calling model_fn.
[MaskRCNN] INFO : ***********************
[MaskRCNN] INFO : Building model graph...
[MaskRCNN] INFO : ***********************
WARNING:tensorflow:Entity <bound method AnchorLayer.call of <iva.mask_rcnn.layers.anchor_layer.AnchorLayer object at 0x7fc7d965cfd0>> could not be transformed and will be executed as-is. Please report this to the AutoGraph team. When filing the bug, set the verbosity to 10 (on Linux, `export AUTOGRAPH_VERBOSITY=10`) and attach the full output. Cause: Unable to locate the source code of <bound method AnchorLayer.call of <iva.mask_rcnn.layers.anchor_layer.AnchorLayer object at 0x7fc7d965cfd0>>. Note that functions defined in certain environments, like the interactive Python shell do not expose their source code. If that is the case, you should to define them in a .py source file. If you are certain the code is graph-compatible, wrap the call using @tf.autograph.do_not_convert. Original error: could not get source code
WARNING:tensorflow:Entity <bound method MultilevelProposal.call of <iva.mask_rcnn.layers.multilevel_proposal_layer.MultilevelProposal object at 0x7fc728677438>> could not be transformed and will be executed as-is. Please report this to the AutoGraph team. When filing the bug, set the verbosity to 10 (on Linux, `export AUTOGRAPH_VERBOSITY=10`) and attach the full output. Cause: Unable to locate the source code of <bound method MultilevelProposal.call of <iva.mask_rcnn.layers.multilevel_proposal_layer.MultilevelProposal object at 0x7fc728677438>>. Note that functions defined in certain environments, like the interactive Python shell do not expose their source code. If that is the case, you should to define them in a .py source file. If you are certain the code is graph-compatible, wrap the call using @tf.autograph.do_not_convert. Original error: could not get source code
[MaskRCNN] INFO : [ROI OPs] Using Batched NMS... Scope: MLP/multilevel_propose_rois/level_2/
[MaskRCNN] INFO : [ROI OPs] Using Batched NMS... Scope: MLP/multilevel_propose_rois/level_3/
[MaskRCNN] INFO : [ROI OPs] Using Batched NMS... Scope: MLP/multilevel_propose_rois/level_4/
[MaskRCNN] INFO : [ROI OPs] Using Batched NMS... Scope: MLP/multilevel_propose_rois/level_5/
[MaskRCNN] INFO : [ROI OPs] Using Batched NMS... Scope: MLP/multilevel_propose_rois/level_6/
WARNING:tensorflow:Entity <bound method ProposalAssignment.call of <iva.mask_rcnn.layers.proposal_assignment_layer.ProposalAssignment object at 0x7fc728548358>> could not be transformed and will be executed as-is. Please report this to the AutoGraph team. When filing the bug, set the verbosity to 10 (on Linux, `export AUTOGRAPH_VERBOSITY=10`) and attach the full output. Cause: Unable to locate the source code of <bound method ProposalAssignment.call of <iva.mask_rcnn.layers.proposal_assignment_layer.ProposalAssignment object at 0x7fc728548358>>. Note that functions defined in certain environments, like the interactive Python shell do not expose their source code. If that is the case, you should to define them in a .py source file. If you are certain the code is graph-compatible, wrap the call using @tf.autograph.do_not_convert. Original error: could not get source code
WARNING:tensorflow:Entity <bound method MultilevelCropResize.call of <iva.mask_rcnn.layers.multilevel_crop_resize_layer.MultilevelCropResize object at 0x7fc728550c50>> could not be transformed and will be executed as-is. Please report this to the AutoGraph team. When filing the bug, set the verbosity to 10 (on Linux, `export AUTOGRAPH_VERBOSITY=10`) and attach the full output. Cause: Unable to locate the source code of <bound method MultilevelCropResize.call of <iva.mask_rcnn.layers.multilevel_crop_resize_layer.MultilevelCropResize object at 0x7fc728550c50>>. Note that functions defined in certain environments, like the interactive Python shell do not expose their source code. If that is the case, you should to define them in a .py source file. If you are certain the code is graph-compatible, wrap the call using @tf.autograph.do_not_convert. Original error: could not get source code
WARNING:tensorflow:Entity <bound method ReshapeLayer.call of <iva.mask_rcnn.layers.reshape_layer.ReshapeLayer object at 0x7fc7282f9fd0>> could not be transformed and will be executed as-is. Please report this to the AutoGraph team. When filing the bug, set the verbosity to 10 (on Linux, `export AUTOGRAPH_VERBOSITY=10`) and attach the full output. Cause: Unable to locate the source code of <bound method ReshapeLayer.call of <iva.mask_rcnn.layers.reshape_layer.ReshapeLayer object at 0x7fc7282f9fd0>>. Note that functions defined in certain environments, like the interactive Python shell do not expose their source code. If that is the case, you should to define them in a .py source file. If you are certain the code is graph-compatible, wrap the call using @tf.autograph.do_not_convert. Original error: could not get source code
WARNING:tensorflow:Entity <bound method ReshapeLayer.call of <iva.mask_rcnn.layers.reshape_layer.ReshapeLayer object at 0x7fc728554208>> could not be transformed and will be executed as-is. Please report this to the AutoGraph team. When filing the bug, set the verbosity to 10 (on Linux, `export AUTOGRAPH_VERBOSITY=10`) and attach the full output. Cause: Unable to locate the source code of <bound method ReshapeLayer.call of <iva.mask_rcnn.layers.reshape_layer.ReshapeLayer object at 0x7fc728554208>>. Note that functions defined in certain environments, like the interactive Python shell do not expose their source code. If that is the case, you should to define them in a .py source file. If you are certain the code is graph-compatible, wrap the call using @tf.autograph.do_not_convert. Original error: could not get source code
WARNING:tensorflow:Entity <bound method ReshapeLayer.call of <iva.mask_rcnn.layers.reshape_layer.ReshapeLayer object at 0x7fc7283010f0>> could not be transformed and will be executed as-is. Please report this to the AutoGraph team. When filing the bug, set the verbosity to 10 (on Linux, `export AUTOGRAPH_VERBOSITY=10`) and attach the full output. Cause: Unable to locate the source code of <bound method ReshapeLayer.call of <iva.mask_rcnn.layers.reshape_layer.ReshapeLayer object at 0x7fc7283010f0>>. Note that functions defined in certain environments, like the interactive Python shell do not expose their source code. If that is the case, you should to define them in a .py source file. If you are certain the code is graph-compatible, wrap the call using @tf.autograph.do_not_convert. Original error: could not get source code
WARNING:tensorflow:Entity <bound method BoxTargetEncoder.call of <iva.mask_rcnn.layers.box_target_encoder.BoxTargetEncoder object at 0x7fc7282b3320>> could not be transformed and will be executed as-is. Please report this to the AutoGraph team. When filing the bug, set the verbosity to 10 (on Linux, `export AUTOGRAPH_VERBOSITY=10`) and attach the full output. Cause: Unable to locate the source code of <bound method BoxTargetEncoder.call of <iva.mask_rcnn.layers.box_target_encoder.BoxTargetEncoder object at 0x7fc7282b3320>>. Note that functions defined in certain environments, like the interactive Python shell do not expose their source code. If that is the case, you should to define them in a .py source file. If you are certain the code is graph-compatible, wrap the call using @tf.autograph.do_not_convert. Original error: could not get source code
WARNING:tensorflow:Entity <bound method ForegroundSelectorForMask.call of <iva.mask_rcnn.layers.foreground_selector_for_mask.ForegroundSelectorForMask object at 0x7fc7282f9e10>> could not be transformed and will be executed as-is. Please report this to the AutoGraph team. When filing the bug, set the verbosity to 10 (on Linux, `export AUTOGRAPH_VERBOSITY=10`) and attach the full output. Cause: Unable to locate the source code of <bound method ForegroundSelectorForMask.call of <iva.mask_rcnn.layers.foreground_selector_for_mask.ForegroundSelectorForMask object at 0x7fc7282f9e10>>. Note that functions defined in certain environments, like the interactive Python shell do not expose their source code. If that is the case, you should to define them in a .py source file. If you are certain the code is graph-compatible, wrap the call using @tf.autograph.do_not_convert. Original error: could not get source code
WARNING:tensorflow:Entity <bound method MultilevelCropResize.call of <iva.mask_rcnn.layers.multilevel_crop_resize_layer.MultilevelCropResize object at 0x7fc7282c16d8>> could not be transformed and will be executed as-is. Please report this to the AutoGraph team. When filing the bug, set the verbosity to 10 (on Linux, `export AUTOGRAPH_VERBOSITY=10`) and attach the full output. Cause: Unable to locate the source code of <bound method MultilevelCropResize.call of <iva.mask_rcnn.layers.multilevel_crop_resize_layer.MultilevelCropResize object at 0x7fc7282c16d8>>. Note that functions defined in certain environments, like the interactive Python shell do not expose their source code. If that is the case, you should to define them in a .py source file. If you are certain the code is graph-compatible, wrap the call using @tf.autograph.do_not_convert. Original error: could not get source code
WARNING:tensorflow:Entity <bound method ReshapeLayer.call of <iva.mask_rcnn.layers.reshape_layer.ReshapeLayer object at 0x7fc7280e8ba8>> could not be transformed and will be executed as-is. Please report this to the AutoGraph team. When filing the bug, set the verbosity to 10 (on Linux, `export AUTOGRAPH_VERBOSITY=10`) and attach the full output. Cause: Unable to locate the source code of <bound method ReshapeLayer.call of <iva.mask_rcnn.layers.reshape_layer.ReshapeLayer object at 0x7fc7280e8ba8>>. Note that functions defined in certain environments, like the interactive Python shell do not expose their source code. If that is the case, you should to define them in a .py source file. If you are certain the code is graph-compatible, wrap the call using @tf.autograph.do_not_convert. Original error: could not get source code
WARNING:tensorflow:Entity <bound method MaskPostprocess.call of <iva.mask_rcnn.layers.mask_postprocess_layer.MaskPostprocess object at 0x7fc7280e8c88>> could not be transformed and will be executed as-is. Please report this to the AutoGraph team. When filing the bug, set the verbosity to 10 (on Linux, `export AUTOGRAPH_VERBOSITY=10`) and attach the full output. Cause: Unable to locate the source code of <bound method MaskPostprocess.call of <iva.mask_rcnn.layers.mask_postprocess_layer.MaskPostprocess object at 0x7fc7280e8c88>>. Note that functions defined in certain environments, like the interactive Python shell do not expose their source code. If that is the case, you should to define them in a .py source file. If you are certain the code is graph-compatible, wrap the call using @tf.autograph.do_not_convert. Original error: could not get source code
4 ops no flops stats due to incomplete shapes.
Parsing Inputs...
[MaskRCNN] INFO : [Training Compute Statistics] 397.5 GFLOPS/image
WARNING:tensorflow:Entity <bound method MaskTargetsLayer.call of <iva.mask_rcnn.layers.mask_targets_layer.MaskTargetsLayer object at 0x7fc7003f70f0>> could not be transformed and will be executed as-is. Please report this to the AutoGraph team. When filing the bug, set the verbosity to 10 (on Linux, `export AUTOGRAPH_VERBOSITY=10`) and attach the full output. Cause: Unable to locate the source code of <bound method MaskTargetsLayer.call of <iva.mask_rcnn.layers.mask_targets_layer.MaskTargetsLayer object at 0x7fc7003f70f0>>. Note that functions defined in certain environments, like the interactive Python shell do not expose their source code. If that is the case, you should to define them in a .py source file. If you are certain the code is graph-compatible, wrap the call using @tf.autograph.do_not_convert. Original error: could not get source code
WARNING:tensorflow:
The TensorFlow contrib module will not be included in TensorFlow 2.0.
For more information, please see:
* https://github.com/tensorflow/community/blob/master/rfcs/20180907-contrib-sunset.md
* https://github.com/tensorflow/addons
* https://github.com/tensorflow/io (for I/O related ops)
If you depend on functionality not listed there, please file an issue.
INFO:tensorflow:Done calling model_fn.
INFO:tensorflow:Graph was finalized.
INFO:tensorflow:Restoring parameters from /tmp/tmpdd62oueg/model.ckpt-0
INFO:tensorflow:Running local_init_op.
INFO:tensorflow:Done running local_init_op.
[GPU 00] Restoring pretrained weights (107 Tensors)
[MaskRCNN] INFO : Pretrained weights loaded with success...
[MaskRCNN] INFO : Saving checkpoints for 0 into /workspace/tao-experiments/mask_rcnn/experiment_dir_unpruned/model.step-0.tlt.
[INFO] Global step 10 (epoch 1/5): total loss: 1.08751 (rpn score loss: 0.50105 rpn box loss: 0.01801 fast_rcnn class loss: 0.00147 fast_rcnn box loss: 0.00000) learning rate: 0.00010
[INFO] Global step 20 (epoch 1/5): total loss: 0.79771 (rpn score loss: 0.21389 rpn box loss: 0.01552 fast_rcnn class loss: 0.00133 fast_rcnn box loss: 0.00000) learning rate: 0.00011
[INFO] Global step 30 (epoch 1/5): total loss: 0.66807 (rpn score loss: 0.09456 rpn box loss: 0.00558 fast_rcnn class loss: 0.00095 fast_rcnn box loss: 0.00000) learning rate: 0.00011
[INFO] Global step 40 (epoch 1/5): total loss: 0.64188 (rpn score loss: 0.05087 rpn box loss: 0.02345 fast_rcnn class loss: 0.00058 fast_rcnn box loss: 0.00000) learning rate: 0.00012
[INFO] Global step 50 (epoch 1/5): total loss: 0.62952 (rpn score loss: 0.04548 rpn box loss: 0.01663 fast_rcnn class loss: 0.00042 fast_rcnn box loss: 0.00000) learning rate: 0.00012
[INFO] Global step 60 (epoch 1/5): total loss: 0.62897 (rpn score loss: 0.03960 rpn box loss: 0.02206 fast_rcnn class loss: 0.00034 fast_rcnn box loss: 0.00000) learning rate: 0.00013
[INFO] Global step 70 (epoch 1/5): total loss: 0.60629 (rpn score loss: 0.02917 rpn box loss: 0.00987 fast_rcnn class loss: 0.00027 fast_rcnn box loss: 0.00000) learning rate: 0.00013
[INFO] Global step 80 (epoch 1/5): total loss: 0.61684 (rpn score loss: 0.04026 rpn box loss: 0.00932 fast_rcnn class loss: 0.00028 fast_rcnn box loss: 0.00000) learning rate: 0.00014
[INFO] Global step 90 (epoch 1/5): total loss: 0.60484 (rpn score loss: 0.03208 rpn box loss: 0.00550 fast_rcnn class loss: 0.00028 fast_rcnn box loss: 0.00000) learning rate: 0.00014
[INFO] Global step 100 (epoch 1/5): total loss: 0.59588 (rpn score loss: 0.02379 rpn box loss: 0.00490 fast_rcnn class loss: 0.00021 fast_rcnn box loss: 0.00000) learning rate: 0.00015
[INFO] Global step 110 (epoch 1/5): total loss: 0.63229 (rpn score loss: 0.05280 rpn box loss: 0.01218 fast_rcnn class loss: 0.00034 fast_rcnn box loss: 0.00000) learning rate: 0.00015
[INFO] Global step 120 (epoch 1/5): total loss: 0.60537 (rpn score loss: 0.02846 rpn box loss: 0.00980 fast_rcnn class loss: 0.00014 fast_rcnn box loss: 0.00000) learning rate: 0.00016
[INFO] Global step 130 (epoch 1/5): total loss: 0.62669 (rpn score loss: 0.01871 rpn box loss: 0.04073 fast_rcnn class loss: 0.00027 fast_rcnn box loss: 0.00000) learning rate: 0.00016
[INFO] Global step 140 (epoch 1/5): total loss: 0.62338 (rpn score loss: 0.03793 rpn box loss: 0.01836 fast_rcnn class loss: 0.00012 fast_rcnn box loss: 0.00000) learning rate: 0.00017
[INFO] Global step 150 (epoch 1/5): total loss: 0.62216 (rpn score loss: 0.03980 rpn box loss: 0.01525 fast_rcnn class loss: 0.00014 fast_rcnn box loss: 0.00000) learning rate: 0.00017
[INFO] Global step 160 (epoch 1/5): total loss: 0.60811 (rpn score loss: 0.02080 rpn box loss: 0.02021 fast_rcnn class loss: 0.00013 fast_rcnn box loss: 0.00000) learning rate: 0.00018
[INFO] Global step 170 (epoch 1/5): total loss: 0.60522 (rpn score loss: 0.02692 rpn box loss: 0.01125 fast_rcnn class loss: 0.00008 fast_rcnn box loss: 0.00000) learning rate: 0.00018
[INFO] Global step 180 (epoch 1/5): total loss: 0.60858 (rpn score loss: 0.02792 rpn box loss: 0.01359 fast_rcnn class loss: 0.00010 fast_rcnn box loss: 0.00000) learning rate: 0.00019
[INFO] Global step 190 (epoch 1/5): total loss: 0.59488 (rpn score loss: 0.02268 rpn box loss: 0.00517 fast_rcnn class loss: 0.00007 fast_rcnn box loss: 0.00000) learning rate: 0.00019
[INFO] Global step 200 (epoch 1/5): total loss: 0.59832 (rpn score loss: 0.02401 rpn box loss: 0.00727 fast_rcnn class loss: 0.00007 fast_rcnn box loss: 0.00000) learning rate: 0.00020
[INFO] Global step 210 (epoch 1/5): total loss: 0.60448 (rpn score loss: 0.02572 rpn box loss: 0.01151 fast_rcnn class loss: 0.00028 fast_rcnn box loss: 0.00000) learning rate: 0.00020
[INFO] Global step 220 (epoch 1/5): total loss: 0.59650 (rpn score loss: 0.01955 rpn box loss: 0.00986 fast_rcnn class loss: 0.00012 fast_rcnn box loss: 0.00000) learning rate: 0.00021
[INFO] Global step 230 (epoch 1/5): total loss: 0.59755 (rpn score loss: 0.01974 rpn box loss: 0.01079 fast_rcnn class loss: 0.00005 fast_rcnn box loss: 0.00000) learning rate: 0.00021
[INFO] Global step 240 (epoch 1/5): total loss: 0.59513 (rpn score loss: 0.02210 rpn box loss: 0.00596 fast_rcnn class loss: 0.00010 fast_rcnn box loss: 0.00000) learning rate: 0.00022
[INFO] Global step 250 (epoch 1/5): total loss: 0.59135 (rpn score loss: 0.01306 rpn box loss: 0.01127 fast_rcnn class loss: 0.00005 fast_rcnn box loss: 0.00000) learning rate: 0.00022
[INFO] Global step 260 (epoch 1/5): total loss: 0.59928 (rpn score loss: 0.02011 rpn box loss: 0.01216 fast_rcnn class loss: 0.00005 fast_rcnn box loss: 0.00000) learning rate: 0.00023
[INFO] Global step 270 (epoch 1/5): total loss: 0.58700 (rpn score loss: 0.01570 rpn box loss: 0.00426 fast_rcnn class loss: 0.00008 fast_rcnn box loss: 0.00000) learning rate: 0.00023
[INFO] Global step 280 (epoch 1/5): total loss: 0.59943 (rpn score loss: 0.01260 rpn box loss: 0.01983 fast_rcnn class loss: 0.00004 fast_rcnn box loss: 0.00000) learning rate: 0.00024
[INFO] Global step 290 (epoch 1/5): total loss: 0.58338 (rpn score loss: 0.01315 rpn box loss: 0.00322 fast_rcnn class loss: 0.00005 fast_rcnn box loss: 0.00000) learning rate: 0.00024
[INFO] Global step 300 (epoch 1/5): total loss: 0.59749 (rpn score loss: 0.01810 rpn box loss: 0.01232 fast_rcnn class loss: 0.00011 fast_rcnn box loss: 0.00000) learning rate: 0.00025
[INFO] Global step 310 (epoch 1/5): total loss: 0.59032 (rpn score loss: 0.01356 rpn box loss: 0.00978 fast_rcnn class loss: 0.00003 fast_rcnn box loss: 0.00000) learning rate: 0.00025
[INFO] Global step 320 (epoch 1/5): total loss: 0.60330 (rpn score loss: 0.02625 rpn box loss: 0.01004 fast_rcnn class loss: 0.00005 fast_rcnn box loss: 0.00000) learning rate: 0.00026
[INFO] Global step 330 (epoch 1/5): total loss: 0.61629 (rpn score loss: 0.03262 rpn box loss: 0.01667 fast_rcnn class loss: 0.00005 fast_rcnn box loss: 0.00000) learning rate: 0.00026
[INFO] Global step 340 (epoch 1/5): total loss: 0.60495 (rpn score loss: 0.02390 rpn box loss: 0.01406 fast_rcnn class loss: 0.00003 fast_rcnn box loss: 0.00000) learning rate: 0.00027
[INFO] Global step 350 (epoch 1/5): total loss: 0.59348 (rpn score loss: 0.01269 rpn box loss: 0.01381 fast_rcnn class loss: 0.00003 fast_rcnn box loss: 0.00000) learning rate: 0.00027
[INFO] Global step 360 (epoch 1/5): total loss: 0.61971 (rpn score loss: 0.03183 rpn box loss: 0.02088 fast_rcnn class loss: 0.00004 fast_rcnn box loss: 0.00000) learning rate: 0.00028
[INFO] Global step 370 (epoch 1/5): total loss: 0.59124 (rpn score loss: 0.02010 rpn box loss: 0.00409 fast_rcnn class loss: 0.00010 fast_rcnn box loss: 0.00000) learning rate: 0.00028
[INFO] Global step 380 (epoch 1/5): total loss: 0.58285 (rpn score loss: 0.01272 rpn box loss: 0.00305 fast_rcnn class loss: 0.00013 fast_rcnn box loss: 0.00000) learning rate: 0.00029
[INFO] Global step 390 (epoch 1/5): total loss: 0.59883 (rpn score loss: 0.02712 rpn box loss: 0.00466 fast_rcnn class loss: 0.00010 fast_rcnn box loss: 0.00000) learning rate: 0.00029
[INFO] Global step 400 (epoch 1/5): total loss: 0.58613 (rpn score loss: 0.01093 rpn box loss: 0.00817 fast_rcnn class loss: 0.00008 fast_rcnn box loss: 0.00000) learning rate: 0.00030
[INFO] Global step 410 (epoch 1/5): total loss: 0.57773 (rpn score loss: 0.00982 rpn box loss: 0.00094 fast_rcnn class loss: 0.00002 fast_rcnn box loss: 0.00000) learning rate: 0.00030
[INFO] Global step 420 (epoch 1/5): total loss: 0.58736 (rpn score loss: 0.01111 rpn box loss: 0.00928 fast_rcnn class loss: 0.00002 fast_rcnn box loss: 0.00000) learning rate: 0.00031
[INFO] Global step 430 (epoch 1/5): total loss: 0.58916 (rpn score loss: 0.01574 rpn box loss: 0.00643 fast_rcnn class loss: 0.00004 fast_rcnn box loss: 0.00000) learning rate: 0.00031
[INFO] Global step 440 (epoch 1/5): total loss: 0.58466 (rpn score loss: 0.00756 rpn box loss: 0.01011 fast_rcnn class loss: 0.00005 fast_rcnn box loss: 0.00000) learning rate: 0.00032
[INFO] Global step 450 (epoch 1/5): total loss: 0.59299 (rpn score loss: 0.01763 rpn box loss: 0.00840 fast_rcnn class loss: 0.00001 fast_rcnn box loss: 0.00000) learning rate: 0.00032
[INFO] Global step 460 (epoch 1/5): total loss: 0.58344 (rpn score loss: 0.01061 rpn box loss: 0.00587 fast_rcnn class loss: 0.00002 fast_rcnn box loss: 0.00000) learning rate: 0.00032
[INFO] Global step 470 (epoch 1/5): total loss: 0.60757 (rpn score loss: 0.01690 rpn box loss: 0.02371 fast_rcnn class loss: 0.00002 fast_rcnn box loss: 0.00000) learning rate: 0.00033
[INFO] Global step 480 (epoch 1/5): total loss: 0.58853 (rpn score loss: 0.01684 rpn box loss: 0.00467 fast_rcnn class loss: 0.00008 fast_rcnn box loss: 0.00000) learning rate: 0.00033
[INFO] Global step 490 (epoch 1/5): total loss: 0.58862 (rpn score loss: 0.00972 rpn box loss: 0.01195 fast_rcnn class loss: 0.00002 fast_rcnn box loss: 0.00000) learning rate: 0.00034
[INFO] Global step 500 (epoch 1/5): total loss: 0.58438 (rpn score loss: 0.01474 rpn box loss: 0.00264 fast_rcnn class loss: 0.00008 fast_rcnn box loss: 0.00000) learning rate: 0.00034
[INFO] Global step 510 (epoch 1/5): total loss: 0.57785 (rpn score loss: 0.00623 rpn box loss: 0.00467 fast_rcnn class loss: 0.00003 fast_rcnn box loss: 0.00000) learning rate: 0.00035
[INFO] Global step 520 (epoch 1/5): total loss: 0.58718 (rpn score loss: 0.01505 rpn box loss: 0.00518 fast_rcnn class loss: 0.00002 fast_rcnn box loss: 0.00000) learning rate: 0.00035
[INFO] Global step 530 (epoch 1/5): total loss: 0.58404 (rpn score loss: 0.01204 rpn box loss: 0.00501 fast_rcnn class loss: 0.00006 fast_rcnn box loss: 0.00000) learning rate: 0.00036
[INFO] Global step 540 (epoch 1/5): total loss: 0.57616 (rpn score loss: 0.00659 rpn box loss: 0.00262 fast_rcnn class loss: 0.00002 fast_rcnn box loss: 0.00000) learning rate: 0.00036
[INFO] Global step 550 (epoch 1/5): total loss: 0.58753 (rpn score loss: 0.01347 rpn box loss: 0.00711 fast_rcnn class loss: 0.00002 fast_rcnn box loss: 0.00000) learning rate: 0.00037
[INFO] Global step 560 (epoch 1/5): total loss: 0.58907 (rpn score loss: 0.01558 rpn box loss: 0.00656 fast_rcnn class loss: 0.00001 fast_rcnn box loss: 0.00000) learning rate: 0.00037
[INFO] Global step 570 (epoch 1/5): total loss: 0.58732 (rpn score loss: 0.01726 rpn box loss: 0.00307 fast_rcnn class loss: 0.00006 fast_rcnn box loss: 0.00000) learning rate: 0.00038
[INFO] Global step 580 (epoch 1/5): total loss: 0.59210 (rpn score loss: 0.01490 rpn box loss: 0.01027 fast_rcnn class loss: 0.00002 fast_rcnn box loss: 0.00000) learning rate: 0.00038
[INFO] Global step 590 (epoch 1/5): total loss: 0.59326 (rpn score loss: 0.01446 rpn box loss: 0.01187 fast_rcnn class loss: 0.00001 fast_rcnn box loss: 0.00000) learning rate: 0.00039
[INFO] Global step 600 (epoch 1/5): total loss: 0.58724 (rpn score loss: 0.01321 rpn box loss: 0.00709 fast_rcnn class loss: 0.00002 fast_rcnn box loss: 0.00000) learning rate: 0.00039
[INFO] Global step 610 (epoch 1/5): total loss: 0.58312 (rpn score loss: 0.00855 rpn box loss: 0.00764 fast_rcnn class loss: 0.00002 fast_rcnn box loss: 0.00000) learning rate: 0.00040
[INFO] Global step 620 (epoch 1/5): total loss: 0.60035 (rpn score loss: 0.02282 rpn box loss: 0.01061 fast_rcnn class loss: 0.00001 fast_rcnn box loss: 0.00000) learning rate: 0.00040
[INFO] Global step 630 (epoch 1/5): total loss: 0.57895 (rpn score loss: 0.00671 rpn box loss: 0.00532 fast_rcnn class loss: 0.00000 fast_rcnn box loss: 0.00000) learning rate: 0.00041
[INFO] Global step 640 (epoch 1/5): total loss: 0.60201 (rpn score loss: 0.01658 rpn box loss: 0.01851 fast_rcnn class loss: 0.00000 fast_rcnn box loss: 0.00000) learning rate: 0.00041
[INFO] Global step 650 (epoch 1/5): total loss: 0.58949 (rpn score loss: 0.01380 rpn box loss: 0.00874 fast_rcnn class loss: 0.00004 fast_rcnn box loss: 0.00000) learning rate: 0.00042
[INFO] Global step 660 (epoch 1/5): total loss: 0.57807 (rpn score loss: 0.00661 rpn box loss: 0.00453 fast_rcnn class loss: 0.00002 fast_rcnn box loss: 0.00000) learning rate: 0.00042
[INFO] Global step 670 (epoch 1/5): total loss: 0.58275 (rpn score loss: 0.01076 rpn box loss: 0.00509 fast_rcnn class loss: 0.00000 fast_rcnn box loss: 0.00000) learning rate: 0.00043
[INFO] Global step 680 (epoch 1/5): total loss: 0.58477 (rpn score loss: 0.01243 rpn box loss: 0.00543 fast_rcnn class loss: 0.00000 fast_rcnn box loss: 0.00000) learning rate: 0.00043
[INFO] Global step 690 (epoch 1/5): total loss: 0.59141 (rpn score loss: 0.00967 rpn box loss: 0.01482 fast_rcnn class loss: 0.00001 fast_rcnn box loss: 0.00000) learning rate: 0.00044
[INFO] Global step 700 (epoch 1/5): total loss: 0.57741 (rpn score loss: 0.00788 rpn box loss: 0.00258 fast_rcnn class loss: 0.00005 fast_rcnn box loss: 0.00000) learning rate: 0.00044
[INFO] Global step 710 (epoch 1/5): total loss: 0.57952 (rpn score loss: 0.00558 rpn box loss: 0.00704 fast_rcnn class loss: 0.00001 fast_rcnn box loss: 0.00000) learning rate: 0.00045
[INFO] Global step 720 (epoch 1/5): total loss: 0.60478 (rpn score loss: 0.02814 rpn box loss: 0.00969 fast_rcnn class loss: 0.00006 fast_rcnn box loss: 0.00000) learning rate: 0.00045
[INFO] Global step 730 (epoch 1/5): total loss: 0.58222 (rpn score loss: 0.01074 rpn box loss: 0.00459 fast_rcnn class loss: 0.00000 fast_rcnn box loss: 0.00000) learning rate: 0.00046
[INFO] Global step 740 (epoch 1/5): total loss: 0.57573 (rpn score loss: 0.00551 rpn box loss: 0.00333 fast_rcnn class loss: 0.00000 fast_rcnn box loss: 0.00000) learning rate: 0.00046
[INFO] Global step 750 (epoch 1/5): total loss: 0.58199 (rpn score loss: 0.01238 rpn box loss: 0.00267 fast_rcnn class loss: 0.00005 fast_rcnn box loss: 0.00000) learning rate: 0.00047
[INFO] Global step 760 (epoch 1/5): total loss: 0.58268 (rpn score loss: 0.00714 rpn box loss: 0.00865 fast_rcnn class loss: 0.00000 fast_rcnn box loss: 0.00000) learning rate: 0.00047
[INFO] Global step 770 (epoch 1/5): total loss: 0.57533 (rpn score loss: 0.00488 rpn box loss: 0.00355 fast_rcnn class loss: 0.00001 fast_rcnn box loss: 0.00000) learning rate: 0.00048
[INFO] Global step 780 (epoch 1/5): total loss: 0.57733 (rpn score loss: 0.00699 rpn box loss: 0.00343 fast_rcnn class loss: 0.00002 fast_rcnn box loss: 0.00000) learning rate: 0.00048
[INFO] Global step 790 (epoch 1/5): total loss: 0.57687 (rpn score loss: 0.00433 rpn box loss: 0.00565 fast_rcnn class loss: 0.00000 fast_rcnn box loss: 0.00000) learning rate: 0.00049
[INFO] Global step 800 (epoch 1/5): total loss: 0.58891 (rpn score loss: 0.00657 rpn box loss: 0.01545 fast_rcnn class loss: 0.00001 fast_rcnn box loss: 0.00000) learning rate: 0.00049
[INFO] Global step 810 (epoch 1/5): total loss: 0.57464 (rpn score loss: 0.00278 rpn box loss: 0.00498 fast_rcnn class loss: 0.00000 fast_rcnn box loss: 0.00000) learning rate: 0.00050
[INFO] Global step 820 (epoch 1/5): total loss: 0.57898 (rpn score loss: 0.00429 rpn box loss: 0.00781 fast_rcnn class loss: 0.00000 fast_rcnn box loss: 0.00000) learning rate: 0.00050
[INFO] Global step 830 (epoch 1/5): total loss: 0.59646 (rpn score loss: 0.00862 rpn box loss: 0.02096 fast_rcnn class loss: 0.00001 fast_rcnn box loss: 0.00000) learning rate: 0.00051
[INFO] Global step 840 (epoch 1/5): total loss: 0.58176 (rpn score loss: 0.00914 rpn box loss: 0.00574 fast_rcnn class loss: 0.00001 fast_rcnn box loss: 0.00000) learning rate: 0.00051
[INFO] Global step 850 (epoch 1/5): total loss: 0.59268 (rpn score loss: 0.01223 rpn box loss: 0.01358 fast_rcnn class loss: 0.00000 fast_rcnn box loss: 0.00000) learning rate: 0.00052
[INFO] Global step 860 (epoch 1/5): total loss: 0.57775 (rpn score loss: 0.00695 rpn box loss: 0.00390 fast_rcnn class loss: 0.00003 fast_rcnn box loss: 0.00000) learning rate: 0.00052
[INFO] Global step 870 (epoch 1/5): total loss: 0.58151 (rpn score loss: 0.01027 rpn box loss: 0.00434 fast_rcnn class loss: 0.00004 fast_rcnn box loss: 0.00000) learning rate: 0.00053
[INFO] Global step 880 (epoch 1/5): total loss: 0.57470 (rpn score loss: 0.00627 rpn box loss: 0.00157 fast_rcnn class loss: 0.00000 fast_rcnn box loss: 0.00000) learning rate: 0.00053
[INFO] Global step 4760 (epoch 1/5): total loss: 0.56648 (rpn score loss: 0.00073 rpn box loss: 0.00147 fast_rcnn class loss: 0.00000 fast_rcnn box loss: 0.00000) learning rate: 0.00243
[INFO] Global step 4770 (epoch 1/5): total loss: 0.56867 (rpn score loss: 0.00126 rpn box loss: 0.00314 fast_rcnn class loss: 0.00000 fast_rcnn box loss: 0.00000) learning rate: 0.00244
[INFO] Global step 4780 (epoch 1/5): total loss: 0.56622 (rpn score loss: 0.00039 rpn box loss: 0.00158 fast_rcnn class loss: 0.00000 fast_rcnn box loss: 0.00000) learning rate: 0.00244
[INFO] Global step 4790 (epoch 1/5): total loss: 0.56783 (rpn score loss: 0.00070 rpn box loss: 0.00288 fast_rcnn class loss: 0.00000 fast_rcnn box loss: 0.00000) learning rate: 0.00245
[INFO] Global step 4800 (epoch 1/5): total loss: 0.56790 (rpn score loss: 0.00135 rpn box loss: 0.00231 fast_rcnn class loss: 0.00000 fast_rcnn box loss: 0.00000) learning rate: 0.00245
[INFO] Global step 4810 (epoch 1/5): total loss: 0.56572 (rpn score loss: 0.00044 rpn box loss: 0.00106 fast_rcnn class loss: 0.00000 fast_rcnn box loss: 0.00000) learning rate: 0.00246
[INFO] Global step 4820 (epoch 1/5): total loss: 0.56665 (rpn score loss: 0.00064 rpn box loss: 0.00180 fast_rcnn class loss: 0.00000 fast_rcnn box loss: 0.00000) learning rate: 0.00246
[INFO] Global step 4830 (epoch 1/5): total loss: 0.56830 (rpn score loss: 0.00250 rpn box loss: 0.00159 fast_rcnn class loss: 0.00002 fast_rcnn box loss: 0.00000) learning rate: 0.00247
[INFO] Global step 4840 (epoch 1/5): total loss: 0.56661 (rpn score loss: 0.00037 rpn box loss: 0.00204 fast_rcnn class loss: 0.00001 fast_rcnn box loss: 0.00000) learning rate: 0.00247
[INFO] Global step 4850 (epoch 1/5): total loss: 0.56827 (rpn score loss: 0.00095 rpn box loss: 0.00314 fast_rcnn class loss: 0.00001 fast_rcnn box loss: 0.00000) learning rate: 0.00248
[INFO] Global step 4860 (epoch 1/5): total loss: 0.56790 (rpn score loss: 0.00094 rpn box loss: 0.00280 fast_rcnn class loss: 0.00000 fast_rcnn box loss: 0.00000) learning rate: 0.00248
[INFO] Global step 4870 (epoch 1/5): total loss: 0.57624 (rpn score loss: 0.00032 rpn box loss: 0.01177 fast_rcnn class loss: 0.00000 fast_rcnn box loss: 0.00000) learning rate: 0.00249
[INFO] Global step 4880 (epoch 1/5): total loss: 0.56798 (rpn score loss: 0.00156 rpn box loss: 0.00227 fast_rcnn class loss: 0.00000 fast_rcnn box loss: 0.00000) learning rate: 0.00249
[INFO] Global step 4890 (epoch 1/5): total loss: 0.56576 (rpn score loss: 0.00064 rpn box loss: 0.00099 fast_rcnn class loss: 0.00000 fast_rcnn box loss: 0.00000) learning rate: 0.00250
[INFO] Global step 4900 (epoch 1/5): total loss: 0.56616 (rpn score loss: 0.00068 rpn box loss: 0.00136 fast_rcnn class loss: 0.00000 fast_rcnn box loss: 0.00000) learning rate: 0.00250
[INFO] Global step 4910 (epoch 1/5): total loss: 0.56732 (rpn score loss: 0.00187 rpn box loss: 0.00133 fast_rcnn class loss: 0.00000 fast_rcnn box loss: 0.00000) learning rate: 0.00251
[INFO] Global step 4920 (epoch 1/5): total loss: 0.56689 (rpn score loss: 0.00118 rpn box loss: 0.00162 fast_rcnn class loss: 0.00000 fast_rcnn box loss: 0.00000) learning rate: 0.00251
[INFO] Global step 4930 (epoch 1/5): total loss: 0.56583 (rpn score loss: 0.00057 rpn box loss: 0.00117 fast_rcnn class loss: 0.00000 fast_rcnn box loss: 0.00000) learning rate: 0.00252
[INFO] Global step 4940 (epoch 1/5): total loss: 0.56624 (rpn score loss: 0.00097 rpn box loss: 0.00120 fast_rcnn class loss: 0.00000 fast_rcnn box loss: 0.00000) learning rate: 0.00252
[INFO] Global step 4950 (epoch 1/5): total loss: 0.56855 (rpn score loss: 0.00236 rpn box loss: 0.00211 fast_rcnn class loss: 0.00001 fast_rcnn box loss: 0.00000) learning rate: 0.00253
[INFO] Global step 4960 (epoch 1/5): total loss: 0.56606 (rpn score loss: 0.00042 rpn box loss: 0.00158 fast_rcnn class loss: 0.00000 fast_rcnn box loss: 0.00000) learning rate: 0.00253
[INFO] Global step 4970 (epoch 1/5): total loss: 0.56694 (rpn score loss: 0.00104 rpn box loss: 0.00185 fast_rcnn class loss: 0.00000 fast_rcnn box loss: 0.00000) learning rate: 0.00253
[INFO] Global step 4980 (epoch 1/5): total loss: 0.56550 (rpn score loss: 0.00102 rpn box loss: 0.00045 fast_rcnn class loss: 0.00001 fast_rcnn box loss: 0.00000) learning rate: 0.00254
[INFO] Global step 4990 (epoch 1/5): total loss: 0.56526 (rpn score loss: 0.00042 rpn box loss: 0.00081 fast_rcnn class loss: 0.00002 fast_rcnn box loss: 0.00000) learning rate: 0.00254
[INFO] Global step 5000 (epoch 1/5): total loss: 0.57696 (rpn score loss: 0.00502 rpn box loss: 0.00792 fast_rcnn class loss: 0.00001 fast_rcnn box loss: 0.00000) learning rate: 0.00255
[MaskRCNN] INFO : Saving checkpoints for 5000 into /workspace/tao-experiments/mask_rcnn/experiment_dir_unpruned/model.step-5000.tlt.
INFO:tensorflow:Loss for final step: 0.5769562.
[MaskRCNN] INFO : =================================
[MaskRCNN] INFO : Start evaluation cycle 01
[MaskRCNN] INFO : =================================
INFO:tensorflow:Using config: {'_model_dir': '/tmp/tmpdd62oueg', '_tf_random_seed': 123, '_save_summary_steps': None, '_save_checkpoints_steps': None, '_save_checkpoints_secs': None, '_session_config': gpu_options {
allow_growth: true
force_gpu_compatible: true
}
allow_soft_placement: true
graph_options {
rewrite_options {
meta_optimizer_iterations: TWO
}
}
, '_keep_checkpoint_max': 20, '_keep_checkpoint_every_n_hours': None, '_log_step_count_steps': None, '_train_distribute': None, '_device_fn': None, '_protocol': None, '_eval_distribute': None, '_experimental_distribute': None, '_experimental_max_worker_delay_secs': None, '_session_creation_timeout_secs': 7200, '_service': None, '_cluster_spec': <tensorflow.python.training.server_lib.ClusterSpec object at 0x7fc7d91b9f28>, '_task_type': 'worker', '_task_id': 0, '_global_id_in_cluster': 0, '_master': '', '_evaluation_master': '', '_is_chief': True, '_num_ps_replicas': 0, '_num_worker_replicas': 1}
[MaskRCNN] INFO : Loading weights from /workspace/tao-experiments/mask_rcnn/experiment_dir_unpruned/model.step-5000.tlt
loading annotations into memory...
Done (t=0.01s)
creating index...
index created!
WARNING:tensorflow:Entity <function InputReader.__call__.<locals>._prefetch_dataset at 0x7fc6803088c8> could not be transformed and will be executed as-is. Please report this to the AutoGraph team. When filing the bug, set the verbosity to 10 (on Linux, `export AUTOGRAPH_VERBOSITY=10`) and attach the full output. Cause: Unable to locate the source code of <function InputReader.__call__.<locals>._prefetch_dataset at 0x7fc6803088c8>. Note that functions defined in certain environments, like the interactive Python shell do not expose their source code. If that is the case, you should to define them in a .py source file. If you are certain the code is graph-compatible, wrap the call using @tf.autograph.do_not_convert. Original error: could not get source code
[MaskRCNN] INFO : [*] Limiting the amount of sample to: 500
WARNING:tensorflow:Entity <function dataset_parser at 0x7fc737a6da60> could not be transformed and will be executed as-is. Please report this to the AutoGraph team. When filing the bug, set the verbosity to 10 (on Linux, `export AUTOGRAPH_VERBOSITY=10`) and attach the full output. Cause: Unable to locate the source code of <function dataset_parser at 0x7fc737a6da60>. Note that functions defined in certain environments, like the interactive Python shell do not expose their source code. If that is the case, you should to define them in a .py source file. If you are certain the code is graph-compatible, wrap the call using @tf.autograph.do_not_convert. Original error: could not get source code
WARNING:tensorflow:The operation `tf.image.convert_image_dtype` will be skipped since the input and output dtypes are identical.
WARNING:tensorflow:The operation `tf.image.convert_image_dtype` will be skipped since the input and output dtypes are identical.
WARNING:tensorflow:The operation `tf.image.convert_image_dtype` will be skipped since the input and output dtypes are identical.
WARNING:tensorflow:The operation `tf.image.convert_image_dtype` will be skipped since the input and output dtypes are identical.
INFO:tensorflow:Calling model_fn.
[MaskRCNN] INFO : ***********************
[MaskRCNN] INFO : Building model graph...
[MaskRCNN] INFO : ***********************
WARNING:tensorflow:Entity <bound method AnchorLayer.call of <iva.mask_rcnn.layers.anchor_layer.AnchorLayer object at 0x7fc67821de80>> could not be transformed and will be executed as-is. Please report this to the AutoGraph team. When filing the bug, set the verbosity to 10 (on Linux, `export AUTOGRAPH_VERBOSITY=10`) and attach the full output. Cause: Unable to locate the source code of <bound method AnchorLayer.call of <iva.mask_rcnn.layers.anchor_layer.AnchorLayer object at 0x7fc67821de80>>. Note that functions defined in certain environments, like the interactive Python shell do not expose their source code. If that is the case, you should to define them in a .py source file. If you are certain the code is graph-compatible, wrap the call using @tf.autograph.do_not_convert. Original error: could not get source code
WARNING:tensorflow:Entity <bound method MultilevelProposal.call of <iva.mask_rcnn.layers.multilevel_proposal_layer.MultilevelProposal object at 0x7fc6706b86d8>> could not be transformed and will be executed as-is. Please report this to the AutoGraph team. When filing the bug, set the verbosity to 10 (on Linux, `export AUTOGRAPH_VERBOSITY=10`) and attach the full output. Cause: Unable to locate the source code of <bound method MultilevelProposal.call of <iva.mask_rcnn.layers.multilevel_proposal_layer.MultilevelProposal object at 0x7fc6706b86d8>>. Note that functions defined in certain environments, like the interactive Python shell do not expose their source code. If that is the case, you should to define them in a .py source file. If you are certain the code is graph-compatible, wrap the call using @tf.autograph.do_not_convert. Original error: could not get source code
[MaskRCNN] INFO : [ROI OPs] Using Batched NMS... Scope: MLP/multilevel_propose_rois/level_2/
[MaskRCNN] INFO : [ROI OPs] Using Batched NMS... Scope: MLP/multilevel_propose_rois/level_3/
[MaskRCNN] INFO : [ROI OPs] Using Batched NMS... Scope: MLP/multilevel_propose_rois/level_4/
[MaskRCNN] INFO : [ROI OPs] Using Batched NMS... Scope: MLP/multilevel_propose_rois/level_5/
[MaskRCNN] INFO : [ROI OPs] Using Batched NMS... Scope: MLP/multilevel_propose_rois/level_6/
WARNING:tensorflow:Entity <bound method MultilevelCropResize.call of <iva.mask_rcnn.layers.multilevel_crop_resize_layer.MultilevelCropResize object at 0x7fc6705ac320>> could not be transformed and will be executed as-is. Please report this to the AutoGraph team. When filing the bug, set the verbosity to 10 (on Linux, `export AUTOGRAPH_VERBOSITY=10`) and attach the full output. Cause: Unable to locate the source code of <bound method MultilevelCropResize.call of <iva.mask_rcnn.layers.multilevel_crop_resize_layer.MultilevelCropResize object at 0x7fc6705ac320>>. Note that functions defined in certain environments, like the interactive Python shell do not expose their source code. If that is the case, you should to define them in a .py source file. If you are certain the code is graph-compatible, wrap the call using @tf.autograph.do_not_convert. Original error: could not get source code
WARNING:tensorflow:Entity <bound method ReshapeLayer.call of <iva.mask_rcnn.layers.reshape_layer.ReshapeLayer object at 0x7fc728456978>> could not be transformed and will be executed as-is. Please report this to the AutoGraph team. When filing the bug, set the verbosity to 10 (on Linux, `export AUTOGRAPH_VERBOSITY=10`) and attach the full output. Cause: Unable to locate the source code of <bound method ReshapeLayer.call of <iva.mask_rcnn.layers.reshape_layer.ReshapeLayer object at 0x7fc728456978>>. Note that functions defined in certain environments, like the interactive Python shell do not expose their source code. If that is the case, you should to define them in a .py source file. If you are certain the code is graph-compatible, wrap the call using @tf.autograph.do_not_convert. Original error: could not get source code
WARNING:tensorflow:Entity <bound method ReshapeLayer.call of <iva.mask_rcnn.layers.reshape_layer.ReshapeLayer object at 0x7fc67056ccc0>> could not be transformed and will be executed as-is. Please report this to the AutoGraph team. When filing the bug, set the verbosity to 10 (on Linux, `export AUTOGRAPH_VERBOSITY=10`) and attach the full output. Cause: Unable to locate the source code of <bound method ReshapeLayer.call of <iva.mask_rcnn.layers.reshape_layer.ReshapeLayer object at 0x7fc67056ccc0>>. Note that functions defined in certain environments, like the interactive Python shell do not expose their source code. If that is the case, you should to define them in a .py source file. If you are certain the code is graph-compatible, wrap the call using @tf.autograph.do_not_convert. Original error: could not get source code
WARNING:tensorflow:Entity <bound method ReshapeLayer.call of <iva.mask_rcnn.layers.reshape_layer.ReshapeLayer object at 0x7fc670452470>> could not be transformed and will be executed as-is. Please report this to the AutoGraph team. When filing the bug, set the verbosity to 10 (on Linux, `export AUTOGRAPH_VERBOSITY=10`) and attach the full output. Cause: Unable to locate the source code of <bound method ReshapeLayer.call of <iva.mask_rcnn.layers.reshape_layer.ReshapeLayer object at 0x7fc670452470>>. Note that functions defined in certain environments, like the interactive Python shell do not expose their source code. If that is the case, you should to define them in a .py source file. If you are certain the code is graph-compatible, wrap the call using @tf.autograph.do_not_convert. Original error: could not get source code
WARNING:tensorflow:Entity <bound method GPUDetections.call of <iva.mask_rcnn.layers.gpu_detection_layer.GPUDetections object at 0x7fc6703fea90>> could not be transformed and will be executed as-is. Please report this to the AutoGraph team. When filing the bug, set the verbosity to 10 (on Linux, `export AUTOGRAPH_VERBOSITY=10`) and attach the full output. Cause: Unable to locate the source code of <bound method GPUDetections.call of <iva.mask_rcnn.layers.gpu_detection_layer.GPUDetections object at 0x7fc6703fea90>>. Note that functions defined in certain environments, like the interactive Python shell do not expose their source code. If that is the case, you should to define them in a .py source file. If you are certain the code is graph-compatible, wrap the call using @tf.autograph.do_not_convert. Original error: could not get source code
WARNING:tensorflow:Entity <bound method MultilevelCropResize.call of <iva.mask_rcnn.layers.multilevel_crop_resize_layer.MultilevelCropResize object at 0x7fc670414240>> could not be transformed and will be executed as-is. Please report this to the AutoGraph team. When filing the bug, set the verbosity to 10 (on Linux, `export AUTOGRAPH_VERBOSITY=10`) and attach the full output. Cause: Unable to locate the source code of <bound method MultilevelCropResize.call of <iva.mask_rcnn.layers.multilevel_crop_resize_layer.MultilevelCropResize object at 0x7fc670414240>>. Note that functions defined in certain environments, like the interactive Python shell do not expose their source code. If that is the case, you should to define them in a .py source file. If you are certain the code is graph-compatible, wrap the call using @tf.autograph.do_not_convert. Original error: could not get source code
WARNING:tensorflow:Entity <bound method ReshapeLayer.call of <iva.mask_rcnn.layers.reshape_layer.ReshapeLayer object at 0x7fc728263eb8>> could not be transformed and will be executed as-is. Please report this to the AutoGraph team. When filing the bug, set the verbosity to 10 (on Linux, `export AUTOGRAPH_VERBOSITY=10`) and attach the full output. Cause: Unable to locate the source code of <bound method ReshapeLayer.call of <iva.mask_rcnn.layers.reshape_layer.ReshapeLayer object at 0x7fc728263eb8>>. Note that functions defined in certain environments, like the interactive Python shell do not expose their source code. If that is the case, you should to define them in a .py source file. If you are certain the code is graph-compatible, wrap the call using @tf.autograph.do_not_convert. Original error: could not get source code
WARNING:tensorflow:Entity <bound method MaskPostprocess.call of <iva.mask_rcnn.layers.mask_postprocess_layer.MaskPostprocess object at 0x7fc6702a2240>> could not be transformed and will be executed as-is. Please report this to the AutoGraph team. When filing the bug, set the verbosity to 10 (on Linux, `export AUTOGRAPH_VERBOSITY=10`) and attach the full output. Cause: Unable to locate the source code of <bound method MaskPostprocess.call of <iva.mask_rcnn.layers.mask_postprocess_layer.MaskPostprocess object at 0x7fc6702a2240>>. Note that functions defined in certain environments, like the interactive Python shell do not expose their source code. If that is the case, you should to define them in a .py source file. If you are certain the code is graph-compatible, wrap the call using @tf.autograph.do_not_convert. Original error: could not get source code
4 ops no flops stats due to incomplete shapes.
Parsing Inputs...
[MaskRCNN] INFO : [Inference Compute Statistics] 385.2 GFLOPS/image
INFO:tensorflow:Done calling model_fn.
INFO:tensorflow:Graph was finalized.
INFO:tensorflow:Restoring parameters from /tmp/tmpdd62oueg/model.ckpt-5000
INFO:tensorflow:Running local_init_op.
INFO:tensorflow:Done running local_init_op.
[MaskRCNN] INFO : Running inference on batch 001/125... - Step Time: 9.3672s - Throughput: 0.4 imgs/s
[MaskRCNN] INFO : Running inference on batch 002/125... - Step Time: 0.2272s - Throughput: 17.6 imgs/s
[MaskRCNN] INFO : Running inference on batch 003/125... - Step Time: 0.2299s - Throughput: 17.4 imgs/s
[MaskRCNN] INFO : Running inference on batch 004/125... - Step Time: 0.2299s - Throughput: 17.4 imgs/s
[MaskRCNN] INFO : Running inference on batch 005/125... - Step Time: 0.2246s - Throughput: 17.8 imgs/s
[MaskRCNN] INFO : Running inference on batch 006/125... - Step Time: 0.2259s - Throughput: 17.7 imgs/s
[MaskRCNN] INFO : Running inference on batch 007/125... - Step Time: 0.2275s - Throughput: 17.6 imgs/s
[MaskRCNN] INFO : Running inference on batch 008/125... - Step Time: 0.2288s - Throughput: 17.5 imgs/s
[MaskRCNN] INFO : Running inference on batch 009/125... - Step Time: 0.2254s - Throughput: 17.7 imgs/s
[MaskRCNN] INFO : Running inference on batch 010/125... - Step Time: 0.2277s - Throughput: 17.6 imgs/s
[MaskRCNN] INFO : Running inference on batch 011/125... - Step Time: 0.2245s - Throughput: 17.8 imgs/s
[MaskRCNN] INFO : Running inference on batch 012/125... - Step Time: 0.2264s - Throughput: 17.7 imgs/s
[MaskRCNN] INFO : Running inference on batch 013/125... - Step Time: 0.2242s - Throughput: 17.8 imgs/s
[MaskRCNN] INFO : Running inference on batch 014/125... - Step Time: 0.2239s - Throughput: 17.9 imgs/s
[MaskRCNN] INFO : Running inference on batch 015/125... - Step Time: 0.2251s - Throughput: 17.8 imgs/s
[MaskRCNN] INFO : Running inference on batch 016/125... - Step Time: 0.2250s - Throughput: 17.8 imgs/s
[MaskRCNN] INFO : Running inference on batch 017/125... - Step Time: 0.2279s - Throughput: 17.6 imgs/s
[MaskRCNN] INFO : Running inference on batch 018/125... - Step Time: 0.2253s - Throughput: 17.8 imgs/s
[MaskRCNN] INFO : Running inference on batch 019/125... - Step Time: 0.2245s - Throughput: 17.8 imgs/s
[MaskRCNN] INFO : Running inference on batch 020/125... - Step Time: 0.2253s - Throughput: 17.8 imgs/s
[MaskRCNN] INFO : Running inference on batch 021/125... - Step Time: 0.2253s - Throughput: 17.8 imgs/s
[MaskRCNN] INFO : Running inference on batch 022/125... - Step Time: 0.2256s - Throughput: 17.7 imgs/s
[MaskRCNN] INFO : Running inference on batch 023/125... - Step Time: 0.2273s - Throughput: 17.6 imgs/s
[MaskRCNN] INFO : Running inference on batch 024/125... - Step Time: 0.2334s - Throughput: 17.1 imgs/s
[MaskRCNN] INFO : Running inference on batch 025/125... - Step Time: 0.2321s - Throughput: 17.2 imgs/s
[MaskRCNN] INFO : Running inference on batch 026/125... - Step Time: 0.2248s - Throughput: 17.8 imgs/s
[MaskRCNN] INFO : Running inference on batch 027/125... - Step Time: 0.2251s - Throughput: 17.8 imgs/s
[MaskRCNN] INFO : Running inference on batch 028/125... - Step Time: 0.2259s - Throughput: 17.7 imgs/s
[MaskRCNN] INFO : Running inference on batch 029/125... - Step Time: 0.2254s - Throughput: 17.7 imgs/s
[MaskRCNN] INFO : Running inference on batch 030/125... - Step Time: 0.2267s - Throughput: 17.6 imgs/s
[MaskRCNN] INFO : Running inference on batch 031/125... - Step Time: 0.2240s - Throughput: 17.9 imgs/s
[MaskRCNN] INFO : Running inference on batch 032/125... - Step Time: 0.2260s - Throughput: 17.7 imgs/s
[MaskRCNN] INFO : Running inference on batch 033/125... - Step Time: 0.2231s - Throughput: 17.9 imgs/s
[MaskRCNN] INFO : Running inference on batch 034/125... - Step Time: 0.2277s - Throughput: 17.6 imgs/s
[MaskRCNN] INFO : Running inference on batch 035/125... - Step Time: 0.2317s - Throughput: 17.3 imgs/s
[MaskRCNN] INFO : Running inference on batch 036/125... - Step Time: 0.2252s - Throughput: 17.8 imgs/s
[MaskRCNN] INFO : Running inference on batch 037/125... - Step Time: 0.2250s - Throughput: 17.8 imgs/s
[MaskRCNN] INFO : Running inference on batch 038/125... - Step Time: 0.2317s - Throughput: 17.3 imgs/s
[MaskRCNN] INFO : Running inference on batch 039/125... - Step Time: 0.2296s - Throughput: 17.4 imgs/s
[MaskRCNN] INFO : Running inference on batch 040/125... - Step Time: 0.2240s - Throughput: 17.9 imgs/s
[MaskRCNN] INFO : Running inference on batch 041/125... - Step Time: 0.2252s - Throughput: 17.8 imgs/s
[MaskRCNN] INFO : Running inference on batch 042/125... - Step Time: 0.2341s - Throughput: 17.1 imgs/s
[MaskRCNN] INFO : Running inference on batch 043/125... - Step Time: 0.2316s - Throughput: 17.3 imgs/s
[MaskRCNN] INFO : Running inference on batch 044/125... - Step Time: 0.2256s - Throughput: 17.7 imgs/s
[MaskRCNN] INFO : Running inference on batch 045/125... - Step Time: 0.2275s - Throughput: 17.6 imgs/s
[MaskRCNN] INFO : Running inference on batch 046/125... - Step Time: 0.2277s - Throughput: 17.6 imgs/s
[MaskRCNN] INFO : Running inference on batch 047/125... - Step Time: 0.2297s - Throughput: 17.4 imgs/s
[MaskRCNN] INFO : Running inference on batch 048/125... - Step Time: 0.2258s - Throughput: 17.7 imgs/s
[MaskRCNN] INFO : Running inference on batch 049/125... - Step Time: 0.2252s - Throughput: 17.8 imgs/s
[MaskRCNN] INFO : Running inference on batch 050/125... - Step Time: 0.2261s - Throughput: 17.7 imgs/s
[MaskRCNN] INFO : Running inference on batch 051/125... - Step Time: 0.2257s - Throughput: 17.7 imgs/s
[MaskRCNN] INFO : Running inference on batch 052/125... - Step Time: 0.2263s - Throughput: 17.7 imgs/s
[MaskRCNN] INFO : Running inference on batch 053/125... - Step Time: 0.2331s - Throughput: 17.2 imgs/s
[MaskRCNN] INFO : Running inference on batch 054/125... - Step Time: 0.2263s - Throughput: 17.7 imgs/s
[MaskRCNN] INFO : Running inference on batch 055/125... - Step Time: 0.2258s - Throughput: 17.7 imgs/s
[MaskRCNN] INFO : Running inference on batch 056/125... - Step Time: 0.2255s - Throughput: 17.7 imgs/s
[MaskRCNN] INFO : Running inference on batch 057/125... - Step Time: 0.2257s - Throughput: 17.7 imgs/s
[MaskRCNN] INFO : Running inference on batch 058/125... - Step Time: 0.2261s - Throughput: 17.7 imgs/s
[MaskRCNN] INFO : Running inference on batch 059/125... - Step Time: 0.2274s - Throughput: 17.6 imgs/s
[MaskRCNN] INFO : Running inference on batch 060/125... - Step Time: 0.2258s - Throughput: 17.7 imgs/s
[MaskRCNN] INFO : Running inference on batch 061/125... - Step Time: 0.2273s - Throughput: 17.6 imgs/s
[MaskRCNN] INFO : Running inference on batch 062/125... - Step Time: 0.2252s - Throughput: 17.8 imgs/s
[MaskRCNN] INFO : Running inference on batch 063/125... - Step Time: 0.2251s - Throughput: 17.8 imgs/s
[MaskRCNN] INFO : Running inference on batch 064/125... - Step Time: 0.2257s - Throughput: 17.7 imgs/s
[MaskRCNN] INFO : Running inference on batch 065/125... - Step Time: 0.2244s - Throughput: 17.8 imgs/s
[MaskRCNN] INFO : Running inference on batch 066/125... - Step Time: 0.2313s - Throughput: 17.3 imgs/s
[MaskRCNN] INFO : Running inference on batch 067/125... - Step Time: 0.2290s - Throughput: 17.5 imgs/s
[MaskRCNN] INFO : Running inference on batch 068/125... - Step Time: 0.2274s - Throughput: 17.6 imgs/s
[MaskRCNN] INFO : Running inference on batch 069/125... - Step Time: 0.2245s - Throughput: 17.8 imgs/s
[MaskRCNN] INFO : Running inference on batch 070/125... - Step Time: 0.2251s - Throughput: 17.8 imgs/s
[MaskRCNN] INFO : Running inference on batch 071/125... - Step Time: 0.2256s - Throughput: 17.7 imgs/s
[MaskRCNN] INFO : Running inference on batch 072/125... - Step Time: 0.2252s - Throughput: 17.8 imgs/s
[MaskRCNN] INFO : Running inference on batch 073/125... - Step Time: 0.2243s - Throughput: 17.8 imgs/s
[MaskRCNN] INFO : Running inference on batch 074/125... - Step Time: 0.2263s - Throughput: 17.7 imgs/s
[MaskRCNN] INFO : Running inference on batch 075/125... - Step Time: 0.2296s - Throughput: 17.4 imgs/s
[MaskRCNN] INFO : Running inference on batch 076/125... - Step Time: 0.2264s - Throughput: 17.7 imgs/s
[MaskRCNN] INFO : Running inference on batch 077/125... - Step Time: 0.2253s - Throughput: 17.8 imgs/s
[MaskRCNN] INFO : Running inference on batch 078/125... - Step Time: 0.2263s - Throughput: 17.7 imgs/s
[MaskRCNN] INFO : Running inference on batch 079/125... - Step Time: 0.2256s - Throughput: 17.7 imgs/s
[MaskRCNN] INFO : Running inference on batch 080/125... - Step Time: 0.2265s - Throughput: 17.7 imgs/s
[MaskRCNN] INFO : Running inference on batch 081/125... - Step Time: 0.2304s - Throughput: 17.4 imgs/s
[MaskRCNN] INFO : Running inference on batch 082/125... - Step Time: 0.2272s - Throughput: 17.6 imgs/s
[MaskRCNN] INFO : Running inference on batch 083/125... - Step Time: 0.2300s - Throughput: 17.4 imgs/s
[MaskRCNN] INFO : Running inference on batch 084/125... - Step Time: 0.2288s - Throughput: 17.5 imgs/s
[MaskRCNN] INFO : Running inference on batch 085/125... - Step Time: 0.2285s - Throughput: 17.5 imgs/s
[MaskRCNN] INFO : Running inference on batch 086/125... - Step Time: 0.2400s - Throughput: 16.7 imgs/s
[MaskRCNN] INFO : Running inference on batch 087/125... - Step Time: 0.2300s - Throughput: 17.4 imgs/s
[MaskRCNN] INFO : Running inference on batch 088/125... - Step Time: 0.2290s - Throughput: 17.5 imgs/s
[MaskRCNN] INFO : Running inference on batch 089/125... - Step Time: 0.2267s - Throughput: 17.6 imgs/s
[MaskRCNN] INFO : Running inference on batch 090/125... - Step Time: 0.2341s - Throughput: 17.1 imgs/s
[MaskRCNN] INFO : Running inference on batch 091/125... - Step Time: 0.2252s - Throughput: 17.8 imgs/s
[MaskRCNN] INFO : Running inference on batch 092/125... - Step Time: 0.2392s - Throughput: 16.7 imgs/s
[MaskRCNN] INFO : Running inference on batch 093/125... - Step Time: 0.2354s - Throughput: 17.0 imgs/s
[MaskRCNN] INFO : Running inference on batch 094/125... - Step Time: 0.2293s - Throughput: 17.4 imgs/s
[MaskRCNN] INFO : Running inference on batch 095/125... - Step Time: 0.2408s - Throughput: 16.6 imgs/s
[MaskRCNN] INFO : Running inference on batch 096/125... - Step Time: 0.2280s - Throughput: 17.5 imgs/s
[MaskRCNN] INFO : Running inference on batch 097/125... - Step Time: 0.2284s - Throughput: 17.5 imgs/s
[MaskRCNN] INFO : Running inference on batch 098/125... - Step Time: 0.2296s - Throughput: 17.4 imgs/s
[MaskRCNN] INFO : Running inference on batch 099/125... - Step Time: 0.2266s - Throughput: 17.7 imgs/s
[MaskRCNN] INFO : Running inference on batch 100/125... - Step Time: 0.2269s - Throughput: 17.6 imgs/s
[MaskRCNN] INFO : Running inference on batch 101/125... - Step Time: 0.2279s - Throughput: 17.6 imgs/s
[MaskRCNN] INFO : Running inference on batch 102/125... - Step Time: 0.2295s - Throughput: 17.4 imgs/s
[MaskRCNN] INFO : Running inference on batch 103/125... - Step Time: 0.2397s - Throughput: 16.7 imgs/s
[MaskRCNN] INFO : Running inference on batch 104/125... - Step Time: 0.2341s - Throughput: 17.1 imgs/s
[MaskRCNN] INFO : Running inference on batch 105/125... - Step Time: 0.2260s - Throughput: 17.7 imgs/s
[MaskRCNN] INFO : Running inference on batch 106/125... - Step Time: 0.2322s - Throughput: 17.2 imgs/s
[MaskRCNN] INFO : Running inference on batch 107/125... - Step Time: 0.2295s - Throughput: 17.4 imgs/s
[MaskRCNN] INFO : Running inference on batch 108/125... - Step Time: 0.2299s - Throughput: 17.4 imgs/s
[MaskRCNN] INFO : Running inference on batch 109/125... - Step Time: 0.2285s - Throughput: 17.5 imgs/s
[MaskRCNN] INFO : Running inference on batch 110/125... - Step Time: 0.2275s - Throughput: 17.6 imgs/s
[MaskRCNN] INFO : Running inference on batch 111/125... - Step Time: 0.2285s - Throughput: 17.5 imgs/s
[MaskRCNN] INFO : Running inference on batch 112/125... - Step Time: 0.2271s - Throughput: 17.6 imgs/s
[MaskRCNN] INFO : Running inference on batch 113/125... - Step Time: 0.2296s - Throughput: 17.4 imgs/s
[MaskRCNN] INFO : Running inference on batch 114/125... - Step Time: 0.2333s - Throughput: 17.1 imgs/s
[MaskRCNN] INFO : Running inference on batch 115/125... - Step Time: 0.2298s - Throughput: 17.4 imgs/s
[MaskRCNN] INFO : Running inference on batch 116/125... - Step Time: 0.2299s - Throughput: 17.4 imgs/s
[MaskRCNN] INFO : Running inference on batch 117/125... - Step Time: 0.2275s - Throughput: 17.6 imgs/s
[MaskRCNN] INFO : Running inference on batch 118/125... - Step Time: 0.2361s - Throughput: 16.9 imgs/s
[MaskRCNN] INFO : Running inference on batch 119/125... - Step Time: 0.2297s - Throughput: 17.4 imgs/s
[MaskRCNN] INFO : Running inference on batch 120/125... - Step Time: 0.2322s - Throughput: 17.2 imgs/s
[MaskRCNN] INFO : Running inference on batch 121/125... - Step Time: 0.2261s - Throughput: 17.7 imgs/s
[MaskRCNN] INFO : Running inference on batch 122/125... - Step Time: 0.2259s - Throughput: 17.7 imgs/s
[MaskRCNN] INFO : Running inference on batch 123/125... - Step Time: 0.2253s - Throughput: 17.8 imgs/s
[MaskRCNN] INFO : Running inference on batch 124/125... - Step Time: 0.2267s - Throughput: 17.6 imgs/s
[MaskRCNN] INFO : Running inference on batch 125/125... - Step Time: 0.2241s - Throughput: 17.9 imgs/s
[MaskRCNN] INFO : Loading and preparing results...
[MaskRCNN] INFO : 0/50000
[MaskRCNN] INFO : 1000/50000
[MaskRCNN] INFO : 2000/50000
[MaskRCNN] INFO : 3000/50000
[MaskRCNN] INFO : 4000/50000
[MaskRCNN] INFO : 5000/50000
[MaskRCNN] INFO : 6000/50000
[MaskRCNN] INFO : 7000/50000
[MaskRCNN] INFO : 8000/50000
[MaskRCNN] INFO : 9000/50000
[MaskRCNN] INFO : 10000/50000
[MaskRCNN] INFO : 11000/50000
[MaskRCNN] INFO : 12000/50000
[MaskRCNN] INFO : 13000/50000
[MaskRCNN] INFO : 14000/50000
[MaskRCNN] INFO : 15000/50000
[MaskRCNN] INFO : 16000/50000
[MaskRCNN] INFO : 17000/50000
[MaskRCNN] INFO : 18000/50000
[MaskRCNN] INFO : 19000/50000
[MaskRCNN] INFO : 20000/50000
[MaskRCNN] INFO : 21000/50000
[MaskRCNN] INFO : 22000/50000
[MaskRCNN] INFO : 23000/50000
[MaskRCNN] INFO : 24000/50000
[MaskRCNN] INFO : 25000/50000
[MaskRCNN] INFO : 26000/50000
[MaskRCNN] INFO : 27000/50000
[MaskRCNN] INFO : 28000/50000
[MaskRCNN] INFO : 29000/50000
[MaskRCNN] INFO : 30000/50000
[MaskRCNN] INFO : 31000/50000
[MaskRCNN] INFO : 32000/50000
[MaskRCNN] INFO : 33000/50000
[MaskRCNN] INFO : 34000/50000
[MaskRCNN] INFO : 35000/50000
[MaskRCNN] INFO : 36000/50000
[MaskRCNN] INFO : 37000/50000
[MaskRCNN] INFO : 38000/50000
[MaskRCNN] INFO : 39000/50000
[MaskRCNN] INFO : 40000/50000
[MaskRCNN] INFO : 41000/50000
[MaskRCNN] INFO : 42000/50000
[MaskRCNN] INFO : 43000/50000
[MaskRCNN] INFO : 44000/50000
[MaskRCNN] INFO : 45000/50000
[MaskRCNN] INFO : 46000/50000
[MaskRCNN] INFO : 47000/50000
[MaskRCNN] INFO : 48000/50000
[MaskRCNN] INFO : 49000/50000
creating index...
index created!
Running per image evaluation...
Evaluate annotation type *bbox*
DONE (t=0.08s).
Accumulating evaluation results...
DONE (t=0.02s).
Average Precision (AP) @[ IoU=0.50:0.95 | area= all | maxDets=100 ] = 0.000
Average Precision (AP) @[ IoU=0.50 | area= all | maxDets=100 ] = 0.000
Average Precision (AP) @[ IoU=0.75 | area= all | maxDets=100 ] = 0.000
Average Precision (AP) @[ IoU=0.50:0.95 | area= small | maxDets=100 ] = -1.000
Average Precision (AP) @[ IoU=0.50:0.95 | area=medium | maxDets=100 ] = 0.000
Average Precision (AP) @[ IoU=0.50:0.95 | area= large | maxDets=100 ] = 0.000
Average Recall (AR) @[ IoU=0.50:0.95 | area= all | maxDets= 1 ] = 0.000
Average Recall (AR) @[ IoU=0.50:0.95 | area= all | maxDets= 10 ] = 0.000
Average Recall (AR) @[ IoU=0.50:0.95 | area= all | maxDets=100 ] = 0.000
Average Recall (AR) @[ IoU=0.50:0.95 | area= small | maxDets=100 ] = -1.000
Average Recall (AR) @[ IoU=0.50:0.95 | area=medium | maxDets=100 ] = 0.000
Average Recall (AR) @[ IoU=0.50:0.95 | area= large | maxDets=100 ] = 0.000
Running per image evaluation...
Evaluate annotation type *segm*
DONE (t=0.29s).
Accumulating evaluation results...
DONE (t=0.02s).
Average Precision (AP) @[ IoU=0.50:0.95 | area= all | maxDets=100 ] = 0.000
Average Precision (AP) @[ IoU=0.50 | area= all | maxDets=100 ] = 0.000
Average Precision (AP) @[ IoU=0.75 | area= all | maxDets=100 ] = 0.000
Average Precision (AP) @[ IoU=0.50:0.95 | area= small | maxDets=100 ] = -1.000
Average Precision (AP) @[ IoU=0.50:0.95 | area=medium | maxDets=100 ] = 0.000
Average Precision (AP) @[ IoU=0.50:0.95 | area= large | maxDets=100 ] = 0.000
Average Recall (AR) @[ IoU=0.50:0.95 | area= all | maxDets= 1 ] = 0.000
Average Recall (AR) @[ IoU=0.50:0.95 | area= all | maxDets= 10 ] = 0.000
Average Recall (AR) @[ IoU=0.50:0.95 | area= all | maxDets=100 ] = 0.000
Average Recall (AR) @[ IoU=0.50:0.95 | area= small | maxDets=100 ] = -1.000
Average Recall (AR) @[ IoU=0.50:0.95 | area=medium | maxDets=100 ] = 0.000
Average Recall (AR) @[ IoU=0.50:0.95 | area= large | maxDets=100 ] = 0.000
[MaskRCNN] INFO : # @@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@ #
[MaskRCNN] INFO : Evaluation Performance Summary
[MaskRCNN] INFO : # @@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@ #
[MaskRCNN] INFO : Average throughput: 17.4 samples/sec
[MaskRCNN] INFO : Total processed steps: 125
[MaskRCNN] INFO : Total processing time: 0.0h 36m 17s
[MaskRCNN] INFO : ==================== Metrics ====================
[MaskRCNN] INFO : AP: 0.000000000
[MaskRCNN] INFO : AP50: 0.000000000
[MaskRCNN] INFO : AP75: 0.000000000
[MaskRCNN] INFO : APl: 0.000000000
[MaskRCNN] INFO : APm: 0.000000000
[MaskRCNN] INFO : APs: -1.000000000
[MaskRCNN] INFO : ARl: 0.000000000
[MaskRCNN] INFO : ARm: 0.000000000
[MaskRCNN] INFO : ARmax1: 0.000000000
[MaskRCNN] INFO : ARmax10: 0.000000000
[MaskRCNN] INFO : ARmax100: 0.000000000
[MaskRCNN] INFO : ARs: -1.000000000
[MaskRCNN] INFO : mask_AP: 0.000000000
[MaskRCNN] INFO : mask_AP50: 0.000000000
[MaskRCNN] INFO : mask_AP75: 0.000000000
[MaskRCNN] INFO : mask_APl: 0.000000000
[MaskRCNN] INFO : mask_APm: 0.000000000
[MaskRCNN] INFO : mask_APs: -1.000000000
[MaskRCNN] INFO : mask_ARl: 0.000000000
[MaskRCNN] INFO : mask_ARm: 0.000000000
[MaskRCNN] INFO : mask_ARmax1: 0.000000000
[MaskRCNN] INFO : mask_ARmax10: 0.000000000
[MaskRCNN] INFO : mask_ARmax100: 0.000000000
[MaskRCNN] INFO : mask_ARs: -1.000000000
DLL 2022-08-05 11:15:01.162127 - Iteration: 5000 Validation Iteration: 5000 AP : 0.0
DLL 2022-08-05 11:15:01.162850 - Iteration: 5000 Validation Iteration: 5000 AP50 : 0.0
DLL 2022-08-05 11:15:01.162899 - Iteration: 5000 Validation Iteration: 5000 AP75 : 0.0
DLL 2022-08-05 11:15:01.162934 - Iteration: 5000 Validation Iteration: 5000 APs : -1.0
DLL 2022-08-05 11:15:01.162964 - Iteration: 5000 Validation Iteration: 5000 APm : 0.0
DLL 2022-08-05 11:15:01.163013 - Iteration: 5000 Validation Iteration: 5000 APl : 0.0
DLL 2022-08-05 11:15:01.163050 - Iteration: 5000 Validation Iteration: 5000 ARmax1 : 0.0
DLL 2022-08-05 11:15:01.163078 - Iteration: 5000 Validation Iteration: 5000 ARmax10 : 0.0
DLL 2022-08-05 11:15:01.163108 - Iteration: 5000 Validation Iteration: 5000 ARmax100 : 0.0
DLL 2022-08-05 11:15:01.163136 - Iteration: 5000 Validation Iteration: 5000 ARs : -1.0
DLL 2022-08-05 11:15:01.163164 - Iteration: 5000 Validation Iteration: 5000 ARm : 0.0
DLL 2022-08-05 11:15:01.163190 - Iteration: 5000 Validation Iteration: 5000 ARl : 0.0
DLL 2022-08-05 11:15:01.163218 - Iteration: 5000 Validation Iteration: 5000 mask_AP : 0.0
DLL 2022-08-05 11:15:01.163246 - Iteration: 5000 Validation Iteration: 5000 mask_AP50 : 0.0
DLL 2022-08-05 11:15:01.163273 - Iteration: 5000 Validation Iteration: 5000 mask_AP75 : 0.0
DLL 2022-08-05 11:15:01.163303 - Iteration: 5000 Validation Iteration: 5000 mask_APs : -1.0
DLL 2022-08-05 11:15:01.163331 - Iteration: 5000 Validation Iteration: 5000 mask_APm : 0.0
DLL 2022-08-05 11:15:01.163357 - Iteration: 5000 Validation Iteration: 5000 mask_APl : 0.0
DLL 2022-08-05 11:15:01.163385 - Iteration: 5000 Validation Iteration: 5000 mask_ARmax1 : 0.0
DLL 2022-08-05 11:15:01.163414 - Iteration: 5000 Validation Iteration: 5000 mask_ARmax10 : 0.0
DLL 2022-08-05 11:15:01.163442 - Iteration: 5000 Validation Iteration: 5000 mask_ARmax100 : 0.0
DLL 2022-08-05 11:15:01.163472 - Iteration: 5000 Validation Iteration: 5000 mask_ARs : -1.0
DLL 2022-08-05 11:15:01.163499 - Iteration: 5000 Validation Iteration: 5000 mask_ARm : 0.0
DLL 2022-08-05 11:15:01.163527 - Iteration: 5000 Validation Iteration: 5000 mask_ARl : 0.0
[MaskRCNN] INFO : =================================
[MaskRCNN] INFO : Start training cycle 02
[MaskRCNN] INFO : =================================
Can you please explain where I am making mistake?
I am attaching json file below.
train.json (787.1 KB)
val.json (757.0 KB)
Thanks.