Riva 2.0.0 comes with default inferencing scripts for ASR/NLP/TTS.
There are streaming scipts also available like - talk_stream.py and transcribe_mic.py
I have downloaded the default models for ASR/TTS (en-US) and tried the python streaming scipts, there I got errors.
USB headset are connected to the system seen at no 24 by using the code -
python3 /work/examples/transcribe_mic.py –list-devices
15: tegra-snd-t19x-mobile-rt565x: - (hw:1,11)
16: tegra-snd-t19x-mobile-rt565x: - (hw:1,12)
17: tegra-snd-t19x-mobile-rt565x: - (hw:1,13)
18: tegra-snd-t19x-mobile-rt565x: - (hw:1,14)
19: tegra-snd-t19x-mobile-rt565x: - (hw:1,15)
20: tegra-snd-t19x-mobile-rt565x: - (hw:1,16)
21: tegra-snd-t19x-mobile-rt565x: - (hw:1,17)
22: tegra-snd-t19x-mobile-rt565x: - (hw:1,18)
23: tegra-snd-t19x-mobile-rt565x: - (hw:1,19)
24: USB Lavalier Microphone: Audio (hw:2,0)
For ASR script, python /work/examples/transcribe_mic.py –input-device=24

For TTS, python /work/examples/talk_stream.py --output-device=24
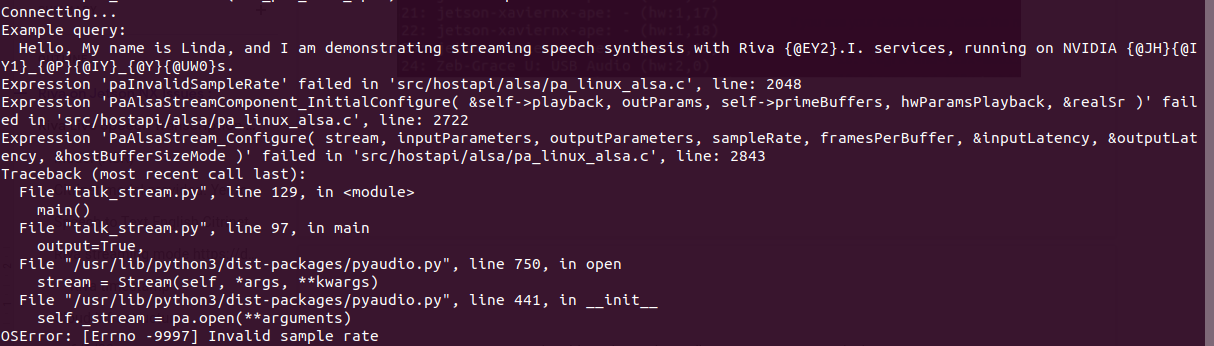
The above error is managed by chnaging samplerate from 44100 to 48000. But I got this below error.
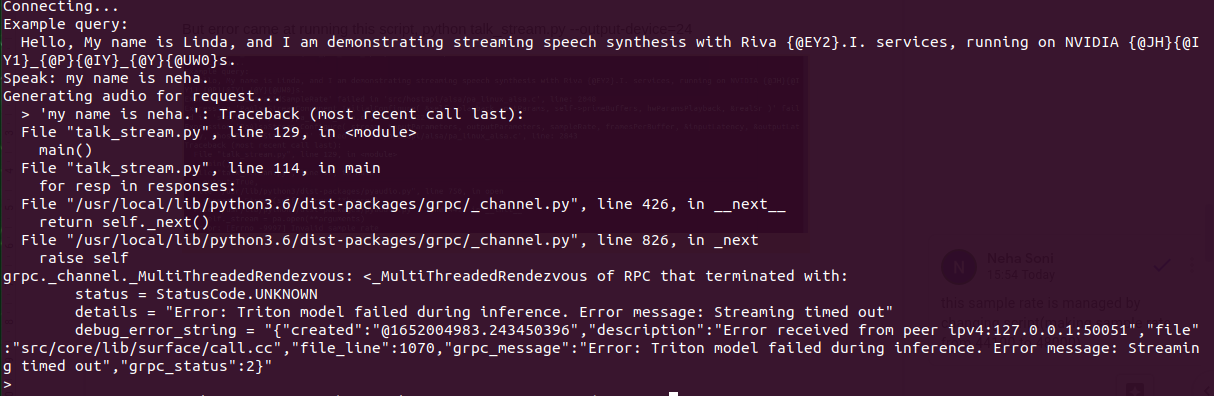
Please provide the following information when requesting support.
Hardware - GPU : Nvidia Xavier NX
Hardware - CPU : Nvidia Xavier NX
Operating System : Jetpack 4.6
Riva Version : 2.0.0
Thanks.