Hello everyone
For an upcoming project, I’m looking for hardware that could support mission-critical AI inferencing software, serving multiple concurrent models with different backends at the same time whilst having control over the maximum allowed latency of certain parts in the software.
After some research, I have identified the following stack:
- Hardware: NVIDIA Orin NX
- Real-Time Operating System: RedHawk Linux (support for Orin is coming)
- Inferencing software: NVIDIA Triton Inference Server
I still have some open questions that I would like to see answered:
- I read on the NVIDIA forums that true hard real-time is not possible on CPUs with caches due to inconsistency in cache misses, so if an RTOS like RedHawk promises hard real-time on the jetson platform, where exactly does it run? The Cortex A78AE have caches, so does it run on the Cortex R52 cores in the Orin safety island (I don’t find much information about this) as some kind of supervisor for a normal Linux?
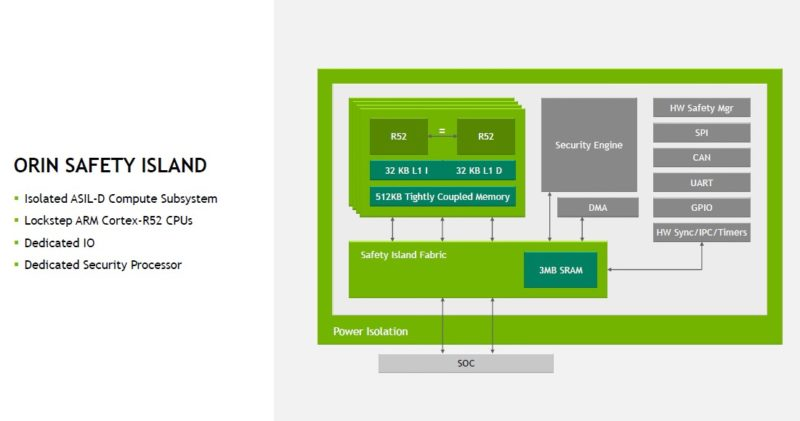
-
I read that CUDA is not supported for RTOS, is this still the case? Say that I would only run an RTOS would that mean that I will not be able to harness the GPU computation capabilities (and how about the AI inferencing cores, NVDLA2.0)? It seems that RedHawk does support CUDA, do they have their own implementation?
-
Does it make sense to run Triton on top of an RTOS on top of the Orin?
Thank you if you can shine some light on any of these questions, or provide some feedback!