Please provide complete information as applicable to your setup.
**• Hardware Platform (Jetson / GPU)**GPU • DeepStream Version6.1.1 • JetPack Version (valid for Jetson only) • TensorRT Version • NVIDIA GPU Driver Version (valid for GPU only) • Issue Type( questions, new requirements, bugs) • How to reproduce the issue ? (This is for bugs. Including which sample app is using, the configuration files content, the command line used and other details for reproducing)
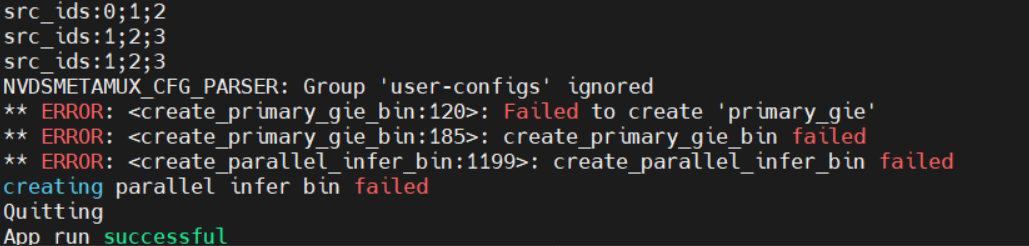
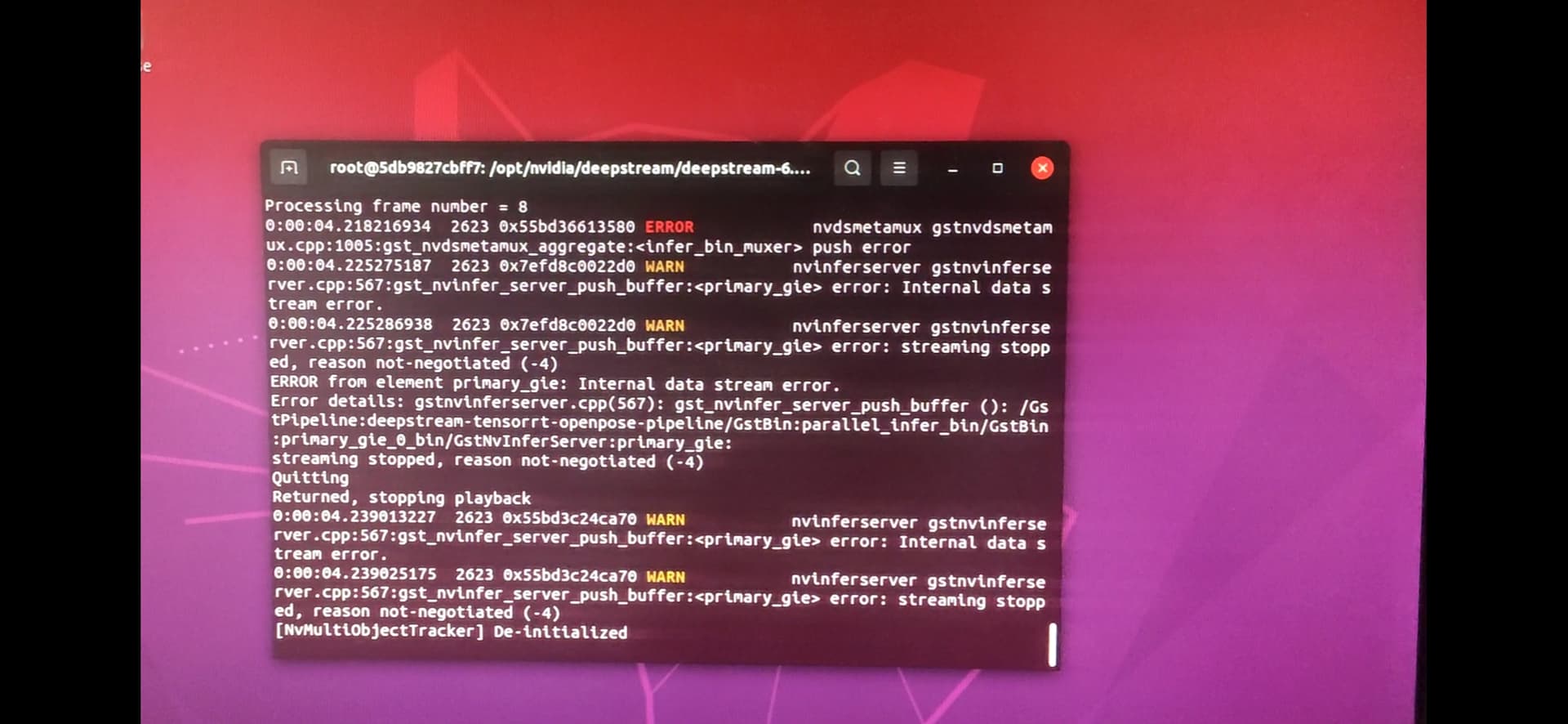
When I run “./apps/deepstream-parallel-infer/deepstream-parallel-infer -c configs/apps/bodypose_yolo_lpr/source4_1080p_dec_parallel_infer.yml” with the repo deepstream_parallel_inference_app , some problems happens as follows:
so, how can I solve this problem? • Requirement details( This is for new requirement. Including the module name-for which plugin or for which sample application, the function description)
And when I modify plugin-type: 0 and config-file: …/…/yolov4/config_yolov4_infer.txt,
there are still error messages, just like:
NVDSMETAMUX_CFG_PARSER: Group ‘user-configs’ ignored
Unknown or leagcy specified ‘is-classifier’ for group [property]
Thanks for your reply, except docker DS6.3, is Docker with DS6.1.1-triton-multiarch available?And what other methods can I use besides docker installs? Looking forward to your reply.
Thansk for your reply sincerely, I run it successfully in docker with docker pull nvcr.io/nvidia/deepstream:6.3-triton-multiarch, and now I want to show video on the screen and display fps on the video or on the terminal, how can I do to achieve it ?
docker run -it --gpus all nvcr.io/nvidia/deepstream:6.3-triton-multiarch /bin/bash
So, do I need to start it completely according to the command you provided?
And, the fps doesn’t support deepstream_parallel_inference_app?😊😊
One more question, how do I use Nsight System to profile?
like this? nsys profile --stats=true ./apps/deepstream-parallel-infer/deepstream-parallel-infer -c configs/apps/bodypose_yolo_lpr/source4_1080.p_dec_parallel_infer.yml
I’m trying to get CPU and GPU utilization