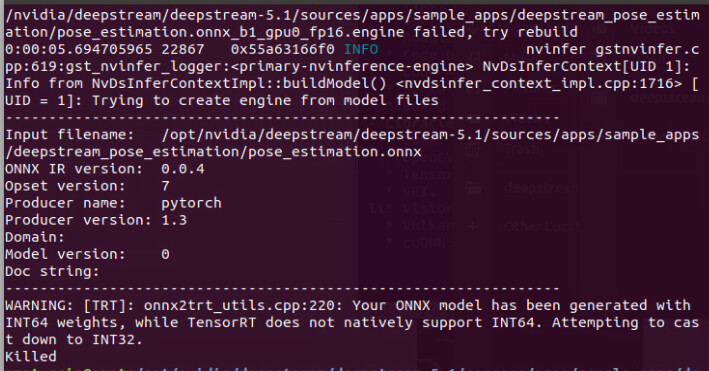
I have check with this command.
Here Are the logs.
RAM 1317/3964MB (lfb 135x4MB) SWAP 831/1982MB (cached 41MB) IRAM 0/252kB(lfb 252kB) CPU [21%@1224,37%@1224,7%@1224,9%@1224] EMC_FREQ 4%@1600 GR3D_FREQ 0%@230 VIC_FREQ 0%@192 APE 25 PLL@26C CPU@30.5C PMIC@100C GPU@26.5C AO@38C thermal@28.5C POM_5V_IN 2628/2927 POM_5V_GPU 78/68 POM_5V_CPU 470/909
RAM 1438/3964MB (lfb 135x4MB) SWAP 831/1982MB (cached 41MB) IRAM 0/252kB(lfb 252kB) CPU [7%@1479,29%@1479,29%@1479,28%@1479] EMC_FREQ 5%@1600 GR3D_FREQ 2%@230 VIC_FREQ 0%@192 APE 25 PLL@27C CPU@30.5C PMIC@100C GPU@26.5C AO@37.5C thermal@28.5C POM_5V_IN 3089/2930 POM_5V_GPU 78/68 POM_5V_CPU 1055/912
RAM 1498/3964MB (lfb 135x4MB) SWAP 831/1982MB (cached 41MB) IRAM 0/252kB(lfb 252kB) CPU [11%@1479,11%@1479,35%@1479,5%@1479] EMC_FREQ 4%@1600 GR3D_FREQ 0%@230 VIC_FREQ 0%@192 APE 25 PLL@26.5C CPU@31.5C PMIC@100C GPU@26.5C AO@37.5C thermal@28.5C POM_5V_IN 2976/2931 POM_5V_GPU 78/68 POM_5V_CPU 1016/913
RAM 1861/3964MB (lfb 135x4MB) SWAP 831/1982MB (cached 41MB) IRAM 0/252kB(lfb 252kB) CPU [15%@1479,14%@1479,51%@1479,7%@1479] EMC_FREQ 5%@1600 GR3D_FREQ 0%@230 VIC_FREQ 0%@192 APE 25 PLL@27C CPU@31.5C PMIC@100C GPU@27C AO@38C thermal@28.5C POM_5V_IN 3167/2935 POM_5V_GPU 78/68 POM_5V_CPU 1094/917
RAM 3515/3964MB (lfb 76x4MB) SWAP 831/1982MB (cached 39MB) IRAM 0/252kB(lfb 252kB) CPU [7%@1479,5%@1479,100%@1479,72%@1479] EMC_FREQ 7%@1600 GR3D_FREQ 0%@76 VIC_FREQ 0%@192 APE 25 PLL@28C CPU@32C PMIC@100C GPU@30C AO@38C thermal@28.75C POM_5V_IN 3891/2952 POM_5V_GPU 0/67 POM_5V_CPU 1942/935
RAM 3562/3964MB (lfb 76x4MB) SWAP 909/1982MB (cached 17MB) IRAM 0/252kB(lfb 252kB) CPU [13%@1479,10%@1479,100%@1479,100%@1479] EMC_FREQ 7%@1600 GR3D_FREQ 0%@76 VIC_FREQ 0%@192 APE 25 PLL@28C CPU@31.5C PMIC@100C GPU@30C AO@37.5C thermal@31C POM_5V_IN 4336/2976 POM_5V_GPU 0/66 POM_5V_CPU 2129/955
RAM 3631/3964MB (lfb 59x4MB) SWAP 1030/1982MB (cached 17MB) IRAM 0/252kB(lfb 252kB) CPU [10%@1479,12%@1479,100%@1479,100%@1479] EMC_FREQ 6%@1600 GR3D_FREQ 0%@76 VIC_FREQ 0%@192 APE 25 PLL@28C CPU@32.5C PMIC@100C GPU@30C AO@38.5C thermal@31C POM_5V_IN 4266/2998 POM_5V_GPU 0/65 POM_5V_CPU 2090/974
RAM 3763/3964MB (lfb 23x4MB) SWAP 1251/1982MB (cached 17MB) IRAM 0/252kB(lfb 252kB) CPU [67%@1479,70%@1479,86%@1479,89%@1479] EMC_FREQ 6%@1600 GR3D_FREQ 0%@76 VIC_FREQ 0%@192 APE 25 PLL@28.5C CPU@32.5C PMIC@100C GPU@27.5C AO@38.5C thermal@29.75C POM_5V_IN 4970/3031 POM_5V_GPU 115/66 POM_5V_CPU 2692/1003
RAM 3792/3964MB (lfb 18x4MB) SWAP 1306/1982MB (cached 1MB) IRAM 0/252kB(lfb 252kB) CPU [11%@1479,61%@1479,100%@1479,25%@1479] EMC_FREQ 5%@1600 GR3D_FREQ 0%@76 VIC_FREQ 0%@192 APE 25 PLL@27.5C CPU@32C PMIC@100C GPU@29.5C AO@38.5C thermal@30.75C POM_5V_IN 3468/3038 POM_5V_GPU 0/65 POM_5V_CPU 1403/1010
RAM 3852/3964MB (lfb 8x4MB) SWAP 1464/1982MB (cached 0MB) IRAM 0/252kB(lfb 252kB) CPU [13%@1479,65%@1479,100%@1479,26%@1479] EMC_FREQ 4%@1600 GR3D_FREQ 0%@76 VIC_FREQ 0%@192 APE 25 PLL@28C CPU@32C PMIC@100C GPU@30C AO@39C thermal@31C POM_5V_IN 4149/3056 POM_5V_GPU 0/64 POM_5V_CPU 2013/1026
RAM 3867/3964MB (lfb 4x4MB) SWAP 1501/1982MB (cached 0MB) IRAM 0/252kB(lfb 252kB) CPU [100%@1479,9%@1479,100%@1479,4%@1479] EMC_FREQ 4%@1600 GR3D_FREQ 0%@76 VIC_FREQ 0%@192 APE 25 PLL@28.5C CPU@32C PMIC@100C GPU@30.5C AO@39C thermal@30.75C POM_5V_IN 4079/3072 POM_5V_GPU 0/62 POM_5V_CPU 2016/1041
RAM 3883/3964MB (lfb 14x2MB) SWAP 1542/1982MB (cached 0MB) IRAM 0/252kB(lfb 252kB) CPU [100%@1479,51%@1479,100%@1479,32%@1479] EMC_FREQ 3%@1600 GR3D_FREQ 0%@76 VIC_FREQ 0%@192 APE 25 PLL@28C CPU@32.5C PMIC@100C GPU@27.5C AO@39C thermal@30C POM_5V_IN 4669/3097 POM_5V_GPU 38/62 POM_5V_CPU 2508/1064
RAM 3888/3964MB (lfb 14x2MB) SWAP 1543/1982MB (cached 0MB) IRAM 0/252kB(lfb 252kB) CPU [100%@1479,98%@1479,100%@1479,95%@1479] EMC_FREQ 3%@1600 GR3D_FREQ 0%@76 VIC_FREQ 0%@192 APE 25 PLL@29C CPU@32.5C PMIC@100C GPU@31C AO@39C thermal@32C POM_5V_IN 5085/3127 POM_5V_GPU 0/61 POM_5V_CPU 3110/1096
RAM 857/3964MB (lfb 89x4MB) SWAP 872/1982MB (cached 3MB) IRAM 0/252kB(lfb 252kB) CPU [81%@1224,80%@1479,86%@1479,85%@1479] EMC_FREQ 3%@1600 GR3D_FREQ 0%@76 VIC_FREQ 0%@192 APE 25 PLL@27.5C CPU@31C PMIC@100C GPU@27C AO@39C thermal@32C POM_5V_IN 2628/3120 POM_5V_GPU 78/61 POM_5V_CPU 431/1086
After this I receive message on terminal kiled.
How Can I solve this issue ?