• Hardware Platform (GPU): Tesla T4 • DeepStream Version: 6.2 • TensorRT Version: 8.5.2.2-1+cuda11.8 • NVIDIA GPU Driver Version: 515.65.01 • Issue Type: Question
Hello,
We have a custom onnx FP32 model. We are trying to convert it to tensorrt FP16. We are converting the model with this command.
/usr/src/tensorrt/bin/trtexec --fp16 --minShapes=input:1x3x480x640 --optShapes=input:32x3x480x640 --maxShapes=input:32x3x480x640 --onnx='/model.onnx' --saveEngine='model_b16.plan' --workspace=7000
While we check model_b16.plan with this flag (–loadEngine), It is showing FP32. It’s not converting in FP16.
So, Kindly guide us on how we can convert our custom onnx FP32 model into tensorrt FP16.
Thanks,
yingliu
February 25, 2023, 4:34am
2
Moving to TensorRT forum for better support.
@yingliu and Nvidia support team,
Hi @daxjain987 ,
Thanks
Yes, We did that.
No, we don’t.link
Hello @AakankshaS ,
We are trying to convert the model.onnx FP32 to a model.plan FP16. And for that, we are using “trtexec” for FP16 model conversion.
While we check the precision of the converted FP16 model using “–loadEngine” flag, it’s showing us FP32 only.
Kindly let us know how to convert our model to FP16 or FP32+FP16 precision only.
Thanks
Hi @daxjain987 ,
Thanks
Hi @AakankshaS ,
You can download the model from here.
We have tried this model to covert it in the FP16 model with this command
/usr/src/tensorrt/bin/trtexec --fp16 --minShapes=input_1:0:1x416x416x3 --optShapes=input_1:0:32x416x416x3 --maxShapes=input_1:0:32x416x416x3 --onnx='yolov4.onnx' --saveEngine='model_b32.plan' --workspace=7000
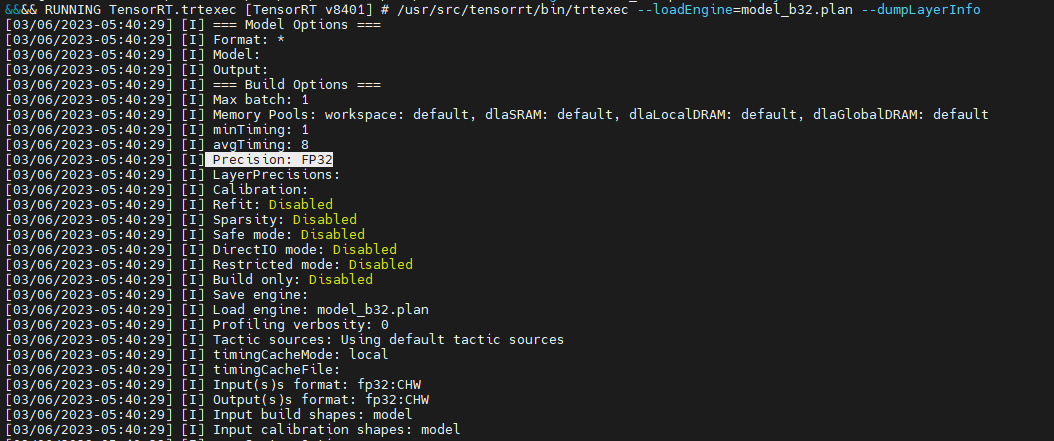
After this conversion, we checked this model with the below command
/usr/src/tensorrt/bin/trtexec --loadEngine=model_b32.plan --dumpLayerInfo
We are getting FP32 precision in logs.
Kindly help us to convert the YOLOv4.onnx model to TRT FP16 model conversion.
Thanks,
Hi @AakankshaS ,
Have you checked the above-highlighted issue?
Looking for your prompt response!!!
Thanks,