Please provide complete information as applicable to your setup.
• Hardware Platform (Jetson / GPU) - RTX A4000
• DeepStream Version - 6.2
• TensorRT Version - 8.5.2
• NVIDIA GPU Driver Version (valid for GPU only) - 525.147.05
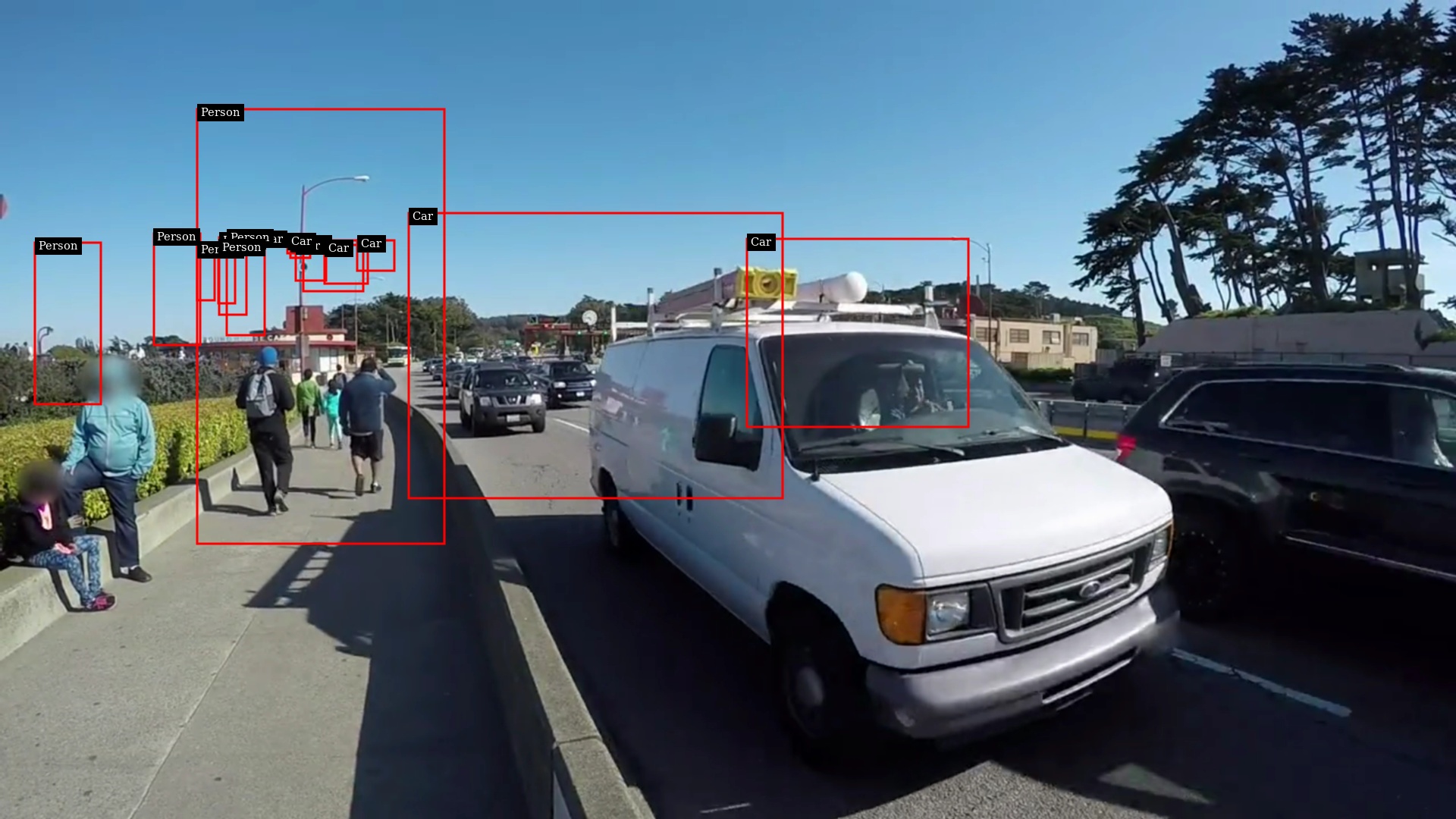
I am trying to save frames based on the detections. For frame extraction, I modified the code using deepstream_opencv_text.c. With that I am using NvBufSurfTransformRect to get the bounding boxes.
The problem is with the bounding boxes, the bounding boxes gets shifted a bit in the extracted frames and comes out to be correct in the streaming video.
Please find the attached code below



> /*
* Copyright (c) 2018-2020, NVIDIA CORPORATION. All rights reserved.
*
* Permission is hereby granted, free of charge, to any person obtaining a
* copy of this software and associated documentation files (the "Software"),
* to deal in the Software without restriction, including without limitation
* the rights to use, copy, modify, merge, publish, distribute, sublicense,
* and/or sell copies of the Software, and to permit persons to whom the
* Software is furnished to do so, subject to the following conditions:
*
* The above copyright notice and this permission notice shall be included in
* all copies or substantial portions of the Software.
*
* THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR
* IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY,
* FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL
* THE AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER
* LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING
* FROM, OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER
* DEALINGS IN THE SOFTWARE.
*/
#include <gst/gst.h>
#include <glib.h>
#include <stdio.h>
#include <unistd.h>
#include <math.h>
#include <string.h>
#include <sys/time.h>
#include <ctype.h>
#include <cuda_runtime_api.h>
#include "nvds_obj_encode.h"
#include "gstnvdsmeta.h"
#include "nvbufsurface.h"
#include "nvbufsurftransform.h"
#include "nvds_obj_encode.h"
#include "opencv4/opencv2/imgproc/imgproc.hpp"
#include "opencv4/opencv2/highgui/highgui.hpp"
//#include "gstnvstreammeta.h"
#ifndef PLATFORM_TEGRA
#include "gst-nvmessage.h"
#endif
#define MAX_DISPLAY_LEN 64
#define PGIE_CLASS_ID_VEHICLE 0
#define PGIE_CLASS_ID_PERSON 2
/* By default, OSD process-mode is set to CPU_MODE. To change mode, set as:
* 1: GPU mode (for Tesla only)
* 2: HW mode (For Jetson only)
*/
#define OSD_PROCESS_MODE 0
/* By default, OSD will not display text. To display text, change this to 1 */
#define OSD_DISPLAY_TEXT 0
/* The muxer output resolution must be set if the input streams will be of
* different resolution. The muxer will scale all the input frames to this
* resolution. */
#define MUXER_OUTPUT_WIDTH 1920
#define MUXER_OUTPUT_HEIGHT 1080
/* Muxer batch formation timeout, for e.g. 40 millisec. Should ideally be set
* based on the fastest source's framerate. */
#define MUXER_BATCH_TIMEOUT_USEC 40000
#define TILED_OUTPUT_WIDTH 1280
#define TILED_OUTPUT_HEIGHT 720
/* NVIDIA Decoder source pad memory feature. This feature signifies that source
* pads having this capability will push GstBuffers containing cuda buffers. */
#define GST_CAPS_FEATURES_NVMM "memory:NVMM"
gchar pgie_classes_str[4][32] = { "Vehicle", "TwoWheeler", "Person",
"RoadSign"
};
#define FPS_PRINT_INTERVAL 300
//static struct timeval start_time = { };
guint frame_count=0;
static GstPadProbeReturn
decode_src_pad_buffer_probe (GstPad * pad, GstPadProbeInfo * info, gpointer u_data)
{
static int flag = 1;
GstBuffer *buf = (GstBuffer *) info->data;
NvDsBatchMeta *batch_meta =
// gst_buffer_get_nvds_batch_meta (GST_BUFFER (info->data));
gst_buffer_get_nvds_batch_meta (buf);
GstMapInfo in_map_info;
NvBufSurface *surface = NULL;
memset (&in_map_info, 0, sizeof (in_map_info));
if (!gst_buffer_map (buf, &in_map_info, GST_MAP_READ)) {
g_print ("Error: Failed to map gst buffer\n");
}
surface = (NvBufSurface *) in_map_info.data;
int batch_size = surface->batchSize;
printf("\nBatch Size : %d, resolution : %dx%d \n",batch_size,
surface->surfaceList[0].width, surface->surfaceList[0].height);
cudaError_t cuda_err;
NvBufSurfTransformRect src_rect, dst_rect;
src_rect.top = 0;
src_rect.left = 0;
src_rect.width = (guint) surface->surfaceList[0].width;
src_rect.height= (guint) surface->surfaceList[0].height;
dst_rect.top = 0;
dst_rect.left = 0;
dst_rect.width = (guint) surface->surfaceList[0].width;
dst_rect.height= (guint) surface->surfaceList[0].height;
NvBufSurfTransformParams nvbufsurface_params;
nvbufsurface_params.src_rect = &src_rect;
nvbufsurface_params.dst_rect = &dst_rect;
nvbufsurface_params.transform_flag = NVBUFSURF_TRANSFORM_FILTER;
nvbufsurface_params.transform_filter = NvBufSurfTransformInter_Default;
NvBufSurface *dst_surface = NULL;
NvBufSurfaceCreateParams nvbufsurface_create_params;
/* An intermediate buffer for NV12/RGBA to BGR conversion will be
* required. Can be skipped if custom algorithm can work directly on NV12/RGBA. */
nvbufsurface_create_params.gpuId = surface->gpuId;
nvbufsurface_create_params.width = (gint) surface->surfaceList[0].width;
nvbufsurface_create_params.height = (gint) surface->surfaceList[0].height;
nvbufsurface_create_params.size = 0;
nvbufsurface_create_params.colorFormat = NVBUF_COLOR_FORMAT_RGBA;
nvbufsurface_create_params.layout = NVBUF_LAYOUT_PITCH;
nvbufsurface_create_params.memType = NVBUF_MEM_CUDA_UNIFIED;
cuda_err = cudaSetDevice (surface->gpuId);
cudaStream_t cuda_stream;
cuda_err=cudaStreamCreate (&cuda_stream);
int create_result = NvBufSurfaceCreate(&dst_surface,batch_size,&nvbufsurface_create_params);
NvBufSurfTransformConfigParams transform_config_params;
NvBufSurfTransform_Error err;
transform_config_params.compute_mode = NvBufSurfTransformCompute_Default;
transform_config_params.gpu_id = surface->gpuId;
transform_config_params.cuda_stream = cuda_stream;
err = NvBufSurfTransformSetSessionParams (&transform_config_params);
NvBufSurfaceMemSet (dst_surface, 0, 0, 0);
err = NvBufSurfTransform (surface, dst_surface, &nvbufsurface_params);
if (err != NvBufSurfTransformError_Success) {
g_print ("NvBufSurfTransform failed with error %d while converting buffer\n", err);
}
NvBufSurfaceMap (dst_surface, 0, 0, NVBUF_MAP_READ);
NvBufSurfaceSyncForCpu (dst_surface, 0, 0);
cv::Mat bgr_frame = cv::Mat (cv::Size(nvbufsurface_create_params.width, nvbufsurface_create_params.height), CV_8UC3);
cv::Mat in_mat =
cv::Mat (nvbufsurface_create_params.height, nvbufsurface_create_params.width,
CV_8UC4, dst_surface->surfaceList[0].mappedAddr.addr[0],
dst_surface->surfaceList[0].pitch);
cv::cvtColor (in_mat, bgr_frame, CV_RGBA2BGR);
if(flag==1) {
cv::imwrite("./output/frame_"+std::to_string(frame_count)+".jpg",bgr_frame);}
// cv::imwrite("./output/out_buf.jpg",bgr_frame);}
NvBufSurfaceUnMap (dst_surface, 0, 0);
NvBufSurfaceDestroy (dst_surface);
cudaStreamDestroy (cuda_stream);
frame_count++;
gst_buffer_unmap (buf, &in_map_info);
// NvBufSurfaceMap (surface, 0, 0, NVBUF_MAP_READ);
// NvBufSurfaceSyncForCpu (surface, 0, 0);
// cv::Mat in_mat =
// cv::Mat (MUXER_OUTPUT_HEIGHT, MUXER_OUTPUT_WIDTH,
// CV_8UC4, surface->surfaceList[0].mappedAddr.addr[0],
// surface->surfaceList[0].pitch);
// cv::Mat out_mat;
// cv::cvtColor (in_mat, out_mat, CV_RGBA2BGR);
// if(flag == 1){ flag = 0; cv::imwrite("out_buf.jpg",out_mat); }
// NvBufSurfaceUnMap (surface, 0, 0);
// NvBufSurfaceDestroy (surface);
// gst_buffer_unmap (buf, &in_map_info);
return GST_PAD_PROBE_OK;
}
static gboolean
bus_call (GstBus * bus, GstMessage * msg, gpointer data)
{
GMainLoop *loop = (GMainLoop *) data;
switch (GST_MESSAGE_TYPE (msg)) {
case GST_MESSAGE_EOS:
g_print ("End of stream\n");
g_main_loop_quit (loop);
break;
case GST_MESSAGE_WARNING:
{
gchar *debug;
GError *error;
gst_message_parse_warning (msg, &error, &debug);
g_printerr ("WARNING from element %s: %s\n",
GST_OBJECT_NAME (msg->src), error->message);
g_free (debug);
g_printerr ("Warning: %s\n", error->message);
g_error_free (error);
break;
}
case GST_MESSAGE_ERROR:
{
gchar *debug;
GError *error;
gst_message_parse_error (msg, &error, &debug);
g_printerr ("ERROR from element %s: %s\n",
GST_OBJECT_NAME (msg->src), error->message);
if (debug)
g_printerr ("Error details: %s\n", debug);
g_free (debug);
g_error_free (error);
g_main_loop_quit (loop);
break;
}
#ifndef PLATFORM_TEGRA
case GST_MESSAGE_ELEMENT:
{
if (gst_nvmessage_is_stream_eos (msg)) {
guint stream_id;
if (gst_nvmessage_parse_stream_eos (msg, &stream_id)) {
g_print ("Got EOS from stream %d\n", stream_id);
}
}
break;
}
#endif
default:
break;
}
return TRUE;
}
static void
cb_newpad (GstElement * decodebin, GstPad * decoder_src_pad, gpointer data)
{
g_print ("In cb_newpad\n");
GstCaps *caps = gst_pad_get_current_caps (decoder_src_pad);
const GstStructure *str = gst_caps_get_structure (caps, 0);
const gchar *name = gst_structure_get_name (str);
GstElement *source_bin = (GstElement *) data;
GstCapsFeatures *features = gst_caps_get_features (caps, 0);
/* Need to check if the pad created by the decodebin is for video and not
* audio. */
if (!strncmp (name, "video", 5)) {
/* Link the decodebin pad only if decodebin has picked nvidia
* decoder plugin nvdec_*. We do this by checking if the pad caps contain
* NVMM memory features. */
if (gst_caps_features_contains (features, GST_CAPS_FEATURES_NVMM)) {
/* Get the source bin ghost pad */
GstPad *bin_ghost_pad = gst_element_get_static_pad (source_bin, "src");
if (!gst_ghost_pad_set_target (GST_GHOST_PAD (bin_ghost_pad),
decoder_src_pad)) {
g_printerr ("Failed to link decoder src pad to source bin ghost pad\n");
}
gst_object_unref (bin_ghost_pad);
} else {
g_printerr ("Error: Decodebin did not pick nvidia decoder plugin.\n");
}
}
}
static void
decodebin_child_added (GstChildProxy * child_proxy, GObject * object,
gchar * name, gpointer user_data)
{
g_print ("Decodebin child added: %s\n", name);
if (g_strrstr (name, "decodebin") == name) {
g_signal_connect (G_OBJECT (object), "child-added",
G_CALLBACK (decodebin_child_added), user_data);
}
}
static GstElement *
create_source_bin (guint index, gchar * uri)
{
GstElement *bin = NULL, *uri_decode_bin = NULL;
gchar bin_name[16] = { };
g_snprintf (bin_name, 15, "source-bin-%02d", index);
/* Create a source GstBin to abstract this bin's content from the rest of the
* pipeline */
bin = gst_bin_new (bin_name);
/* Source element for reading from the uri.
* We will use decodebin and let it figure out the container format of the
* stream and the codec and plug the appropriate demux and decode plugins. */
uri_decode_bin = gst_element_factory_make ("uridecodebin", "uri-decode-bin");
if (!bin || !uri_decode_bin) {
g_printerr ("One element in source bin could not be created.\n");
return NULL;
}
/* We set the input uri to the source element */
g_object_set (G_OBJECT (uri_decode_bin), "uri", uri, NULL);
/* Connect to the "pad-added" signal of the decodebin which generates a
* callback once a new pad for raw data has beed created by the decodebin */
g_signal_connect (G_OBJECT (uri_decode_bin), "pad-added",
G_CALLBACK (cb_newpad), bin);
g_signal_connect (G_OBJECT (uri_decode_bin), "child-added",
G_CALLBACK (decodebin_child_added), bin);
gst_bin_add (GST_BIN (bin), uri_decode_bin);
/* We need to create a ghost pad for the source bin which will act as a proxy
* for the video decoder src pad. The ghost pad will not have a target right
* now. Once the decode bin creates the video decoder and generates the
* cb_newpad callback, we will set the ghost pad target to the video decoder
* src pad. */
if (!gst_element_add_pad (bin, gst_ghost_pad_new_no_target ("src",
GST_PAD_SRC))) {
g_printerr ("Failed to add ghost pad in source bin\n");
return NULL;
}
return bin;
}
int
main (int argc, char *argv[])
{
GMainLoop *loop = NULL;
GstElement *pipeline = NULL, *streammux = NULL, *sink = NULL, *pgie = NULL,
*queue1, *queue2, *queue3, *queue4, *queue5, *nvvidconv = NULL,
*nvosd = NULL, *tiler = NULL;
GstElement *transform = NULL;
GstBus *bus = NULL;
guint bus_watch_id;
GstPad *tiler_src_pad = NULL;
guint i, num_sources;
guint tiler_rows, tiler_columns;
guint pgie_batch_size;
GstElement *tee, *queue6,*vidconv, *encoder, *filesink, *queue7,*nvvidconv2,*nvosd2;
GstPad *tee1;
int current_device = -1;
cudaGetDevice(¤t_device);
struct cudaDeviceProp prop;
cudaGetDeviceProperties(&prop, current_device);
/* Check input arguments */
if (argc < 2) {
g_printerr ("Usage: %s <uri1> [uri2] ... [uriN] \n", argv[0]);
return -1;
}
num_sources = argc - 1;
/* Standard GStreamer initialization */
gst_init (&argc, &argv);
loop = g_main_loop_new (NULL, FALSE);
/* Create gstreamer elements */
/* Create Pipeline element that will form a connection of other elements */
pipeline = gst_pipeline_new ("dstest3-pipeline");
/* Create nvstreammux instance to form batches from one or more sources. */
streammux = gst_element_factory_make ("nvstreammux", "stream-muxer");
tee = gst_element_factory_make("tee","tee_element");
queue6 = gst_element_factory_make ("queue","video-queue-6");
encoder = gst_element_factory_make ("nvv4l2h264enc","video-encoder");
filesink = gst_element_factory_make ("fakesink","videosink-sink");
vidconv = gst_element_factory_make ("nvvideoconvert", "nvvideo-converter2");
queue7 = gst_element_factory_make ("queue","video-queue-7");
GstElement *queue8 = gst_element_factory_make ("queue","video-queue-8");
nvvidconv2= gst_element_factory_make ("nvvideoconvert", "nvvideo-converter-2");
nvosd2 = gst_element_factory_make ("nvdsosd", "nv-onscreendisplay-2");
//g_object_set (G_OBJECT (filesink), "location", "sample1.h264", NULL);
if (!pipeline || !streammux) {
g_printerr ("One element could not be created. Exiting.\n");
return -1;
}
gst_bin_add (GST_BIN (pipeline), streammux);
for (i = 0; i < num_sources; i++) {
GstPad *sinkpad, *srcpad;
gchar pad_name[16] = { };
GstElement *source_bin = create_source_bin (i, argv[i + 1]);
if (!source_bin) {
g_printerr ("Failed to create source bin. Exiting.\n");
return -1;
}
gst_bin_add (GST_BIN (pipeline), source_bin);
g_snprintf (pad_name, 15, "sink_%u", i);
sinkpad = gst_element_get_request_pad (streammux, pad_name);
if (!sinkpad) {
g_printerr ("Streammux request sink pad failed. Exiting.\n");
return -1;
}
srcpad = gst_element_get_static_pad (source_bin, "src");
if (!srcpad) {
g_printerr ("Failed to get src pad of source bin. Exiting.\n");
return -1;
}
if (gst_pad_link (srcpad, sinkpad) != GST_PAD_LINK_OK) {
g_printerr ("Failed to link source bin to stream muxer. Exiting.\n");
return -1;
}
gst_object_unref (srcpad);
gst_object_unref (sinkpad);
}
/* Use nvinfer to infer on batched frame. */
pgie = gst_element_factory_make ("nvinfer", "primary-nvinference-engine");
/* Add queue elements between every two elements */
queue1 = gst_element_factory_make ("queue", "queue1");
queue2 = gst_element_factory_make ("queue", "queue2");
queue3 = gst_element_factory_make ("queue", "queue3");
queue4 = gst_element_factory_make ("queue", "queue4");
queue5 = gst_element_factory_make ("queue", "queue5");
/* Use nvtiler to composite the batched frames into a 2D tiled array based
* on the source of the frames. */
tiler = gst_element_factory_make ("nvmultistreamtiler", "nvtiler");
/* Use convertor to convert from NV12 to RGBA as required by nvosd */
nvvidconv = gst_element_factory_make ("nvvideoconvert", "nvvideo-converter");
/* Create OSD to draw on the converted RGBA buffer */
nvosd = gst_element_factory_make ("nvdsosd", "nv-onscreendisplay");
/* Finally render the osd output */
if(prop.integrated) {
transform = gst_element_factory_make ("nvegltransform", "nvegl-transform");
}
sink = gst_element_factory_make ("nveglglessink", "nvvideo-renderer");
GstElement *nvsink = gst_element_factory_make ("fpsdisplaysink", "fps-display");
g_object_set (G_OBJECT(nvsink),"text-overlay",FALSE,"video-sink",sink,"sync",FALSE,NULL);
if (!pgie || !tiler || !nvvidconv || !nvosd || !sink) {
g_printerr ("One element could not be created. Exiting.\n");
return -1;
}
if(!transform && prop.integrated) {
g_printerr ("One tegra element could not be created. Exiting.\n");
return -1;
}
g_object_set (G_OBJECT (streammux), "batch-size", num_sources, NULL);
g_object_set (G_OBJECT (streammux), "width", MUXER_OUTPUT_WIDTH, "height",
MUXER_OUTPUT_HEIGHT,
"batched-push-timeout", MUXER_BATCH_TIMEOUT_USEC, NULL);
/* Configure the nvinfer element using the nvinfer config file. */
g_object_set (G_OBJECT (pgie),
"config-file-path", "dstest3_pgie_config.txt", NULL);
/* Override the batch-size set in the config file with the number of sources. */
g_object_get (G_OBJECT (pgie), "batch-size", &pgie_batch_size, NULL);
if (pgie_batch_size != num_sources) {
g_printerr
("WARNING: Overriding infer-config batch-size (%d) with number of sources (%d)\n",
pgie_batch_size, num_sources);
g_object_set (G_OBJECT (pgie), "batch-size", num_sources, NULL);
}
tiler_rows = (guint) sqrt (num_sources);
tiler_columns = (guint) ceil (1.0 * num_sources / tiler_rows);
/* we set the tiler properties here */
g_object_set (G_OBJECT (tiler), "rows", tiler_rows, "columns", tiler_columns,
"width", TILED_OUTPUT_WIDTH, "height", TILED_OUTPUT_HEIGHT, NULL);
g_object_set (G_OBJECT (nvosd), "process-mode", OSD_PROCESS_MODE,
"display-text", OSD_DISPLAY_TEXT, NULL);
g_object_set (G_OBJECT (sink), "qos", 0, NULL);
/* we add a message handler */
bus = gst_pipeline_get_bus (GST_PIPELINE (pipeline));
bus_watch_id = gst_bus_add_watch (bus, bus_call, loop);
gst_object_unref (bus);
gst_bin_add_many (GST_BIN (pipeline), queue1, pgie, queue2, tiler, queue3,
nvvidconv, queue4, nvosd, tee,queue5, sink, queue6,vidconv,encoder,filesink,queue7,nvvidconv2,queue8,nvosd2,nvsink,NULL);
if(prop.integrated)
{
gst_bin_add(GST_BIN(pipeline),transform);
}
// if (!gst_element_link_many (streammux, queue1, pgie, queue2, tiler, queue3,
// nvvidconv, queue4, nvosd, tee,NULL)) {
// g_printerr ("Elements could not be linked. Exiting.\n");
// return -1;
// }
if (!gst_element_link_many (streammux, queue1, pgie, tee,NULL)) {
g_printerr ("Elements could not be linked. Exiting.\n");
return -1;
}
/* Set up the pipeline */
/* we add all elements into the pipeline */
if(prop.integrated) {
/* we link the elements together
* nvstreammux -> nvinfer -> nvtiler -> nvvidconv -> nvosd -> video-renderer */
if (!gst_element_link_many (queue2, tiler, queue3, nvvidconv,queue4,nvosd,queue5,transform,sink,NULL)) {
g_printerr ("Elements could not be linked. Exiting.\n");
return -1;
}
}
else {
/* we link the elements together
* nvstreammux -> nvinfer -> nvtiler -> nvvidconv -> nvosd -> video-renderer */
if (!gst_element_link_many (queue2, tiler, queue3, nvvidconv,queue4,nvosd,queue5, sink, NULL)) {
g_printerr ("Elements could not be linked. Exiting.\n");
return -1;
}
}
if (!gst_element_link_many (queue6,nvvidconv2,queue7,nvosd2,queue8,vidconv,encoder,filesink,NULL)) {
g_printerr ("Elements could not be linked. Exiting.\n");
return -1;
}
/* Lets add probe to get informed of the meta data generated, we add probe to
* the sink pad of the osd element, since by that time, the buffer would have
* had got all the metadata. */
tee1 = gst_element_get_request_pad(tee,"src_%u");
if (!tee1) {
g_printerr ("tee request sink pad failed. Exiting.\n");
return -1;
}
GstPad *queuePad = gst_element_get_static_pad (queue2, "sink");
if (!queuePad) {
g_printerr ("Failed to get src pad of source bin. Exiting.\n");
return -1;
}
if (gst_pad_link (tee1, queuePad) != GST_PAD_LINK_OK) {
g_printerr ("Failed to link source bin to stream muxer. Exiting.\n");
return -1;
}
gst_object_unref (tee1);
gst_object_unref (queuePad);
GstPad *tee2 = gst_element_get_request_pad(tee,"src_%u");
if (!tee2) {
g_printerr ("tee request sink pad failed. Exiting.\n");
return -1;
}
GstPad *queuePad2 = gst_element_get_static_pad (queue6, "sink");
if (!queuePad2) {
g_printerr ("Failed to get src pad of source bin. Exiting.\n");
return -1;
}
if (gst_pad_link (tee2, queuePad2) != GST_PAD_LINK_OK) {
g_printerr ("Failed to link source bin to stream muxer. Exiting.\n");
return -1;
}
gst_object_unref (tee2);
gst_object_unref (queuePad2);
// tiler_src_pad = gst_element_get_static_pad (queue6, "sink");
// if (!tiler_src_pad)
// g_print ("Unable to get src pad\n");
// else
// gst_pad_add_probe (tiler_src_pad, GST_PAD_PROBE_TYPE_BUFFER,
// tiler_src_pad_buffer_probe , NULL, NULL);
// gst_object_unref (tiler_src_pad);
GstPad * osd_sink_pad = gst_element_get_static_pad (vidconv, "sink");
if (!osd_sink_pad)
g_print ("Unable to get sink pad\n");
else
gst_pad_add_probe (osd_sink_pad, GST_PAD_PROBE_TYPE_BUFFER,
decode_src_pad_buffer_probe, (gpointer) nvsink, NULL);
gst_object_unref (osd_sink_pad);
/* Set the pipeline to "playing" state */
g_print ("Now playing:");
for (i = 0; i < num_sources; i++) {
g_print (" %s,", argv[i + 1]);
}
g_print ("\n");
gst_element_set_state (pipeline, GST_STATE_PLAYING);
/* Wait till pipeline encounters an error or EOS */
g_print ("Running...\n");
g_main_loop_run (loop);
/* Out of the main loop, clean up nicely */
g_print ("Returned, stopping playback\n");
gst_element_set_state (pipeline, GST_STATE_NULL);
g_print ("Deleting pipeline\n");
gst_object_unref (GST_OBJECT (pipeline));
g_source_remove (bus_watch_id);
g_main_loop_unref (loop);
return 0;
}