It is extremely hard to download the package, failure rate is way too high and basically forbids any automation.
System with yum-axelget does not work because when some connections returned the correct binary while others returned text “Failed to connect to origin, please retry” and essentially invalidate the entire download, causing an amplification of traffic in retry by >100x
This issue has been there for years without a fix, bringing so much pain to us every time we update nvidia packages.
We even end up creating local mirror of repo manually just to make automation (e.g. deployment scripts/docker builds/…) possible.
This reply is speculative but based on observation. Over the past several (5+, if memory serves) years various users from within the PRC have reported issues accessing various portions of NVIDIA’s web site, including downloads of machine-learning related materials. Often these issues would manifest as “strange” error messages.
In all cases that I remember these issues magically disappeared when those users switched to access via VPN (via Hongkong?). This suggests that these access issues were related to the Great Firewall of China. My understanding is that (1) use of VPN in the PRC is highly regulated; (2) the Great Firewall has been enhanced over the years to be largely impervious to attempts to bypass it with VPN.
I note that at this time there may also be a potentially generic issue with international access to NVIDIA’s site that seems tentatively associated with the CDN, as discussed in this thread: Online Documentation for old CUDA Versions
For GFW related issue (i.e. GFW standing between user and website gateway), it will show up as broken SSL connections, not strange messages.
First I’m not seeing any man-in-the-middle attack because cert is valid.
Then the “failed to connect to origin, please retry” we got is not an error code, it is plain text in HTTP response body.
It’s probably saying CDN gateway has trouble accessing upstream server.
If you use VPN, yes it can resolve this issue sometimes, but not because you jump over GFW.
It’s just because you show up in another geo location and connect to a different gateway.
Here’s the trace from curl of redirections in China:
As you can see:
200 from .cn
Seems all these are handled by krill.zenlogic.net.
With VPN nvidia gateway simply gives us 200 from .com, that’s what solves the issue, not “jumping over GFW”.
And interestingly, we usually get error when talking to .cn server (200 but timeout with partial response, 200 with error msg in body, “Failed to ssl_handshake: closed”, …)
And there’re more corrupted cases:
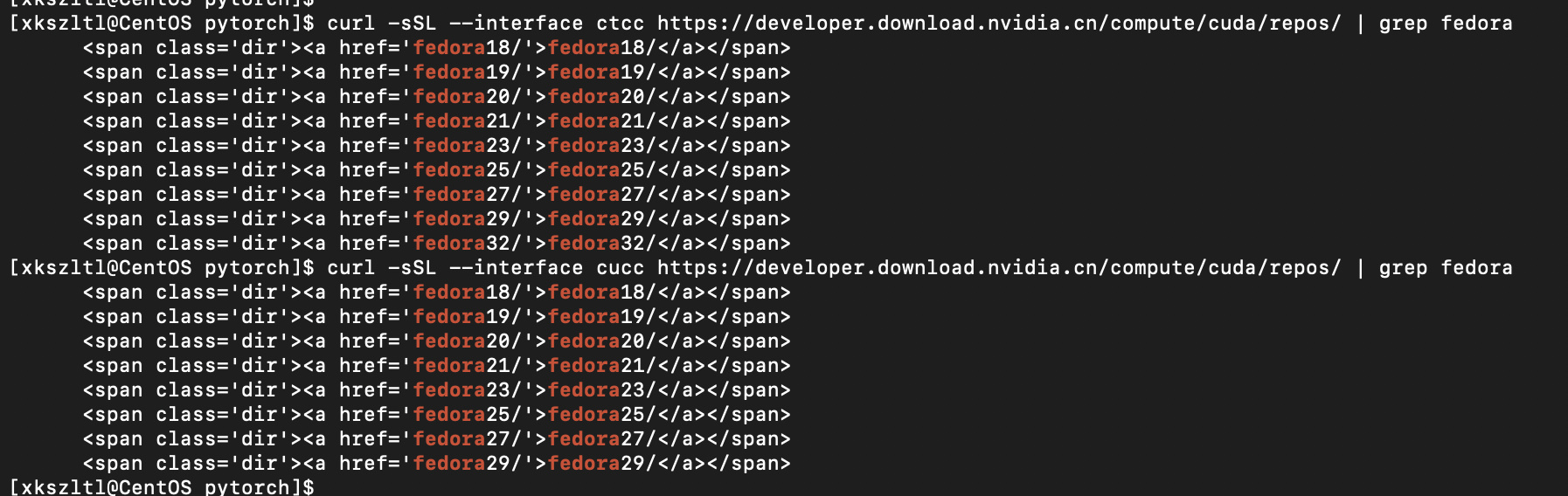
For example I can randomly get different “valid” response.
This example shows result returned by different ISP (China Telcom/China Unicom, 2 largest ISP in China) can be different, China Unicom result does not have Fedora 32 listed (response was not truncated, it simply don’t have that entry in list).
And some pkgs also keep come and go.
For example, only a small potion of response has cuda-runtime-11-1, majority of them only have up to 11-0 as below.
This is purely random, every curl has a different answer.