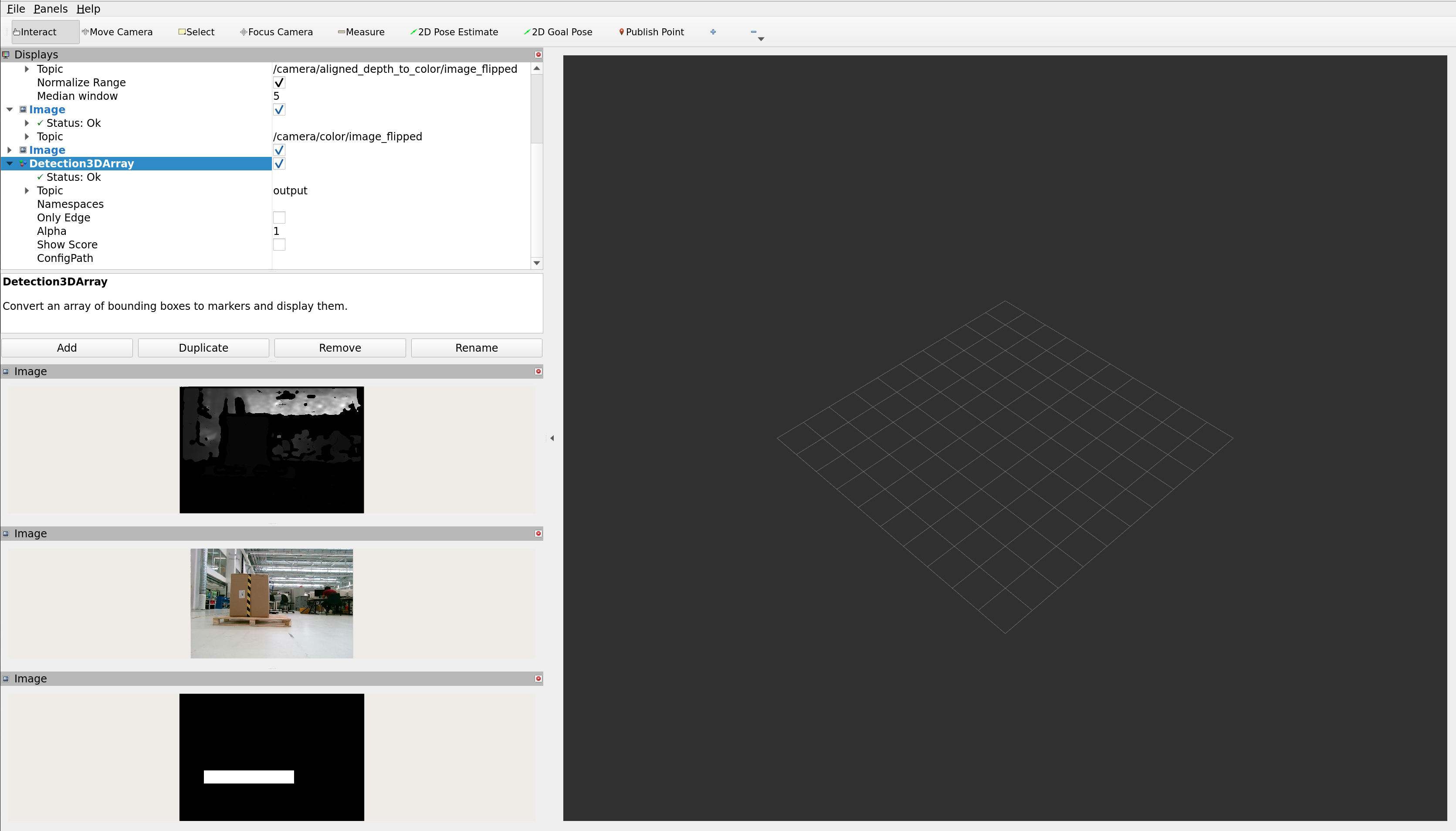
I ran the sdetr_amr model on r2b_storage bag from r2b dataset 2023 | NVIDIA NGC and the model was not able to detect the pallets. Please find attached the screenshots.
Screnshot 1:
Screnshot 2:
My launch command is ros2 launch isaac_ros_rtdetr.launch.py launch_fragments:=rtdetr interface_specs_file:=${ISAAC_ROS_WS}/isaac_ros_assets/isaac_ros_rtdetr/quickstart_interface_specs.json engine_file_path:=${ISAAC_ROS_WS}/isaac_ros_assets/models/synthetica_detr/sdetr_amr.plan and the corresponding launch file is pasted below,
# SPDX-FileCopyrightText: NVIDIA CORPORATION & AFFILIATES
# Copyright (c) 2024 NVIDIA CORPORATION & AFFILIATES. All rights reserved.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
#
# SPDX-License-Identifier: Apache-2.0
import launch
from launch.actions import DeclareLaunchArgument
from launch.substitutions import LaunchConfiguration
from launch_ros.actions import ComposableNodeContainer
from launch_ros.descriptions import ComposableNode
MODEL_INPUT_SIZE = 640 # RT-DETR models expect 640x640 encoded image size
MODEL_NUM_CHANNELS = 3 # RT-DETR models expect 3 image channels
def generate_launch_description():
"""Generate launch description for testing relevant nodes."""
launch_args = [
DeclareLaunchArgument(
'model_file_path',
default_value='',
description='The absolute file path to the ONNX file'),
DeclareLaunchArgument(
'engine_file_path',
default_value='',
description='The absolute file path to the TensorRT engine file'),
DeclareLaunchArgument(
'input_image_width',
default_value='640',
description='The input image width'),
DeclareLaunchArgument(
'input_image_height',
default_value='480',
description='The input image height'),
DeclareLaunchArgument(
'input_tensor_names',
default_value='["images", "orig_target_sizes"]',
description='A list of tensor names to bound to the specified input binding names'),
DeclareLaunchArgument(
'input_binding_names',
default_value='["images", "orig_target_sizes"]',
description='A list of input tensor binding names (specified by model)'),
DeclareLaunchArgument(
'output_tensor_names',
default_value='["labels", "boxes", "scores"]',
description='A list of tensor names to bound to the specified output binding names'),
DeclareLaunchArgument(
'output_binding_names',
default_value='["labels", "boxes", "scores"]',
description='A list of output tensor binding names (specified by model)'),
DeclareLaunchArgument(
'verbose',
default_value='False',
description='Whether TensorRT should verbosely log or not'),
DeclareLaunchArgument(
'force_engine_update',
default_value='False',
description='Whether TensorRT should update the TensorRT engine file or not'),
]
# Image Encoding parameters
input_image_width = LaunchConfiguration('input_image_width')
input_image_height = LaunchConfiguration('input_image_height')
# TensorRT parameters
model_file_path = LaunchConfiguration('model_file_path')
engine_file_path = LaunchConfiguration('engine_file_path')
input_tensor_names = LaunchConfiguration('input_tensor_names')
input_binding_names = LaunchConfiguration('input_binding_names')
output_tensor_names = LaunchConfiguration('output_tensor_names')
output_binding_names = LaunchConfiguration('output_binding_names')
verbose = LaunchConfiguration('verbose')
force_engine_update = LaunchConfiguration('force_engine_update')
resize_node = ComposableNode(
name='resize_node',
package='isaac_ros_image_proc',
plugin='nvidia::isaac_ros::image_proc::ResizeNode',
parameters=[{
'input_width': input_image_width,
'input_height': input_image_height,
'output_width': MODEL_INPUT_SIZE,
'output_height': MODEL_INPUT_SIZE,
'keep_aspect_ratio': True,
'encoding_desired': 'rgb8',
'disable_padding': True
}],
remappings=[
#('image', '/camera/color/image_flipped'),
('image', 'd455_1_rgb_image'),
#('camera_info', '/camera/color/camera_info')
('camera_info', 'd455_1_rgb_camera_info')
]
)
pad_node = ComposableNode(
name='pad_node',
package='isaac_ros_image_proc',
plugin='nvidia::isaac_ros::image_proc::PadNode',
parameters=[{
'output_image_width': MODEL_INPUT_SIZE,
'output_image_height': MODEL_INPUT_SIZE,
'padding_type': 'BOTTOM_RIGHT'
}],
remappings=[(
'image', 'resize/image'
)]
)
image_format_node = ComposableNode(
name='image_format_node',
package='isaac_ros_image_proc',
plugin='nvidia::isaac_ros::image_proc::ImageFormatConverterNode',
parameters=[{
'encoding_desired': 'rgb8',
'image_width': MODEL_INPUT_SIZE,
'image_height': MODEL_INPUT_SIZE
}],
remappings=[
('image_raw', 'padded_image'),
('image', 'image_rgb')]
)
image_to_tensor_node = ComposableNode(
name='image_to_tensor_node',
package='isaac_ros_tensor_proc',
plugin='nvidia::isaac_ros::dnn_inference::ImageToTensorNode',
parameters=[{
'scale': False,
'tensor_name': 'image',
}],
remappings=[
('image', 'image_rgb'),
('tensor', 'normalized_tensor'),
]
)
interleave_to_planar_node = ComposableNode(
name='interleaved_to_planar_node',
package='isaac_ros_tensor_proc',
plugin='nvidia::isaac_ros::dnn_inference::InterleavedToPlanarNode',
parameters=[{
'input_tensor_shape': [MODEL_INPUT_SIZE, MODEL_INPUT_SIZE, MODEL_NUM_CHANNELS]
}],
remappings=[
('interleaved_tensor', 'normalized_tensor')
]
)
reshape_node = ComposableNode(
name='reshape_node',
package='isaac_ros_tensor_proc',
plugin='nvidia::isaac_ros::dnn_inference::ReshapeNode',
parameters=[{
'output_tensor_name': 'input_tensor',
'input_tensor_shape': [MODEL_NUM_CHANNELS, MODEL_INPUT_SIZE, MODEL_INPUT_SIZE],
'output_tensor_shape': [1, MODEL_NUM_CHANNELS, MODEL_INPUT_SIZE, MODEL_INPUT_SIZE]
}],
remappings=[
('tensor', 'planar_tensor')
],
)
rtdetr_preprocessor_node = ComposableNode(
name='rtdetr_preprocessor',
package='isaac_ros_rtdetr',
plugin='nvidia::isaac_ros::rtdetr::RtDetrPreprocessorNode',
remappings=[
('encoded_tensor', 'reshaped_tensor')
]
)
tensor_rt_node = ComposableNode(
name='tensor_rt',
package='isaac_ros_tensor_rt',
plugin='nvidia::isaac_ros::dnn_inference::TensorRTNode',
parameters=[{
'model_file_path': model_file_path,
'engine_file_path': engine_file_path,
'output_binding_names': output_binding_names,
'output_tensor_names': output_tensor_names,
'input_tensor_names': input_tensor_names,
'input_binding_names': input_binding_names,
'verbose': verbose,
'force_engine_update': force_engine_update
}]
)
rtdetr_decoder_node = ComposableNode(
name='rtdetr_decoder',
package='isaac_ros_rtdetr',
plugin='nvidia::isaac_ros::rtdetr::RtDetrDecoderNode',
parameters=[{
'confidence_threshold': 0.5
}]
)
container = ComposableNodeContainer(
name='rtdetr_container',
namespace='rtdetr_container',
package='rclcpp_components',
executable='component_container_mt',
composable_node_descriptions=[
resize_node, pad_node, image_format_node,
image_to_tensor_node, interleave_to_planar_node, reshape_node,
rtdetr_preprocessor_node, tensor_rt_node, rtdetr_decoder_node
],
output='screen'
)
final_launch_description = launch_args + [container]
return launch.LaunchDescription(final_launch_description)
Please provide pointers on why is this the case.
Many Thanks