Can I run an object detection inference in Isaac Sim 2022.x? I saw the Isaac SDK inference examples but version of the SDK is not updated for almost 2 years at this subject or version.
Hi @MuratKOSE. I’m not sure about this one. I’ll move this question to the Isaac Sim forum. They’ll have a better idea.
Hi @MuratKOSE - Someone from our team will respond to your question shortly.
Can you please provide some more info when you say running object detection inference in Isaac Sim?
Meanwhile, you can review this docs and let us know if these documents help you:
@MuratKOSE you can run inference in Isaac Sim, but not through Isaac SDK bridge, you can run it through ROS. For example you can use this Isaac ROS Dope inference with Isaac Sim
I know I can use ROS in Isaac Sim and visualize it somewhere else but my purpose is different. What I mean is can we run inference in Isaac Sim’s viewport? I want to run my TAO model in simulation see the interactions in viewport like in image below but with my object detection model.
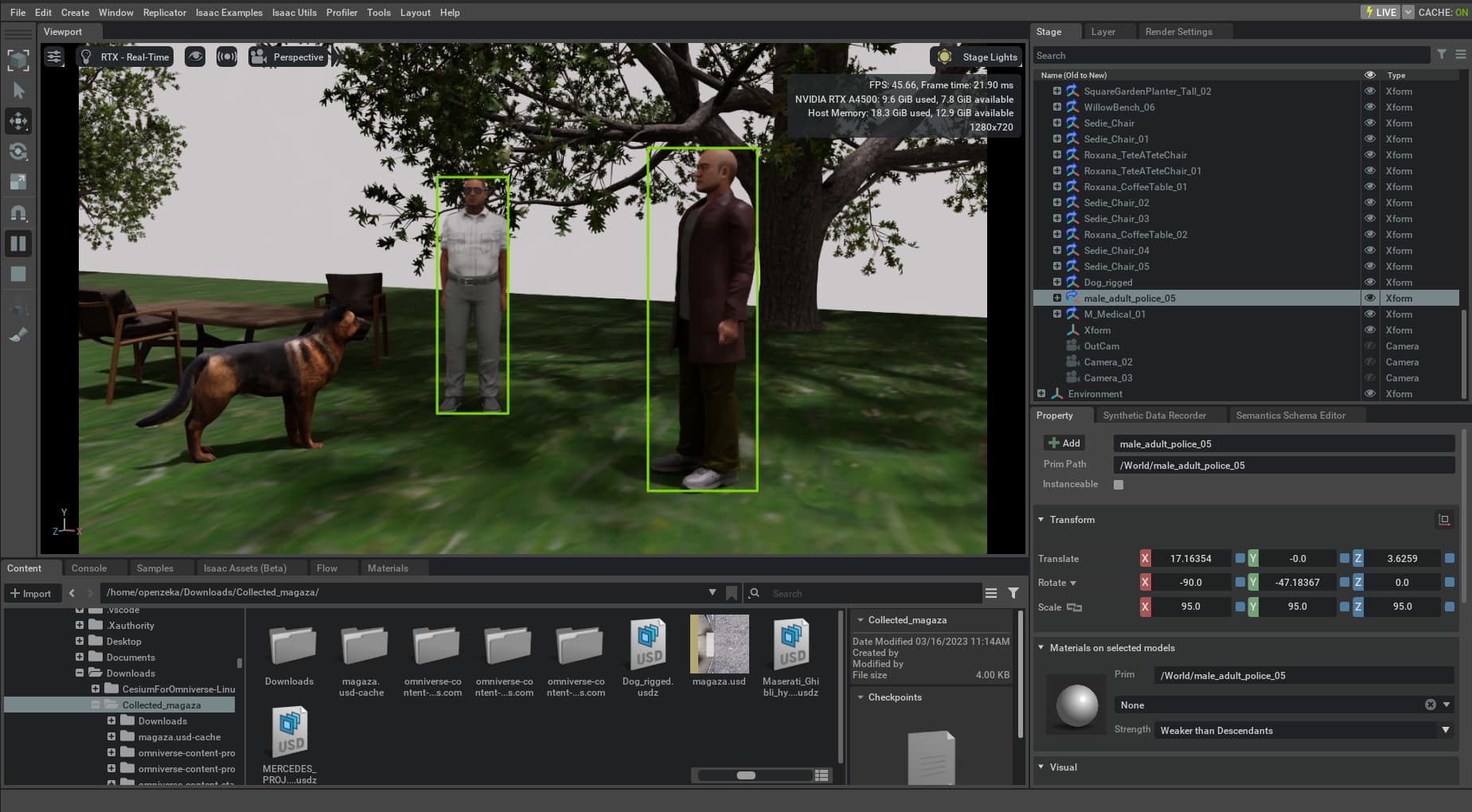
Yes, you should be able to do that
How can I do that? Is there any tool for that?
Hello!
We actually had a live stream about this subject today, and you might find it helpful. You can find it here

here’s the resulting code from the stream
import torch
from torch import Tensor
import numpy as np
from functools import partial
import ctypes
from PIL import Image
import omni.kit.viewport.utility as viewport_utils
from omni.kit.widget.viewport.capture import ByteCapture
import matplotlib.pyplot as plt
def on_capture_completed(db, buffer, buffer_size, width, height, format):
"""
print("buffer", buffer)
print("buffer_size", buffer_size)
print("width", width)
print("height", height)
print("format", format)
"""
ctypes.pythonapi.PyCapsule_GetPointer.restype = ctypes.POINTER(ctypes.c_byte * buffer_size)
ctypes.pythonapi.PyCapsule_GetPointer.argtypes = [ctypes.py_object, ctypes.c_char_p]
content = ctypes.pythonapi.PyCapsule_GetPointer(buffer, None)
img_content = content.contents
db.internal_state.img_buffer = Image.frombytes("RGBA", (width, height), img_content)
def setup(db):
viewport_api = viewport_utils.get_active_viewport()
if "Encoder" not in db.internal_state.__dict__:
import sys
sys.path.append("D:/LiveCoding")
import model
from model import DummyVAE
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
name = db.inputs.file_name
code_dims = 512
img_buffer = None
coder = DummyVAE(3,100,100, code_dims).to(device)
db.internal_state.__dict__['Encoder'] = coder
db.internal_state.__dict__['device'] = device
db.internal_state.__dict__['img_buffer'] = img_buffer
capture = viewport_api.schedule_capture(ByteCapture(partial(on_capture_completed, db), aov_name='LdrColor'))
def compute(db):
model = db.internal_state.Encoder
device = db.internal_state.device
viewport_api = viewport_utils.get_active_viewport()
capture = viewport_api.schedule_capture(ByteCapture(partial(on_capture_completed, db), aov_name='LdrColor'))
image = db.internal_state.img_buffer
if image is not None:
print("it's not none!")
image = image.resize((100,100), Image.Resampling.LANCZOS)
data = np.array(image)
# plt.imshow(data)
# plt.savefig("D:\LiveCoding\image.png")
data = torch.permute(torch.from_numpy(data),(2,0,1)).float()[0:3,...]/255.0
_ , mu, log_var = model(data.unsqueeze(0).to(device))
# print("mu", mu)
db.outputs.out_data = mu.detach().cpu().numpy()
else:
print("it's none!")
def cleanup(db):
pass
the TlDr here is, this is a stop-gap workaround that can be used while we make our sensors and omnigraph more robust. In the stream, we create a script node and use the above script to rip the render product from the viewport, cast it to a numpy array, and activate a model on it.
hope this helps!
Gus
2 Likes
Thanks. I have been looking forward to this…
I know, I’m sorry man. I feel your pain, believe me!
You may also find these helpful. There are multiple documents about script nodes but i have found this one to be the most useful so far Script Node — omni.graph.docs 1.3.2 documentation
1 Like
This topic was automatically closed 14 days after the last reply. New replies are no longer allowed.